

Abstract
After decades of use in dictation and, more recently, ambient documentation, speech is emerging as a primary modality for interacting with technology and AI in healthcare. Yet medical speech recognition remains difficult: systems must capture specialized terminology, resolve contextual ambiguity, and render measurements, abbreviations, and clinical shorthand precisely. Existing solutions are typically optimized either for general-purpose transcription or narrow dictation workflows, limiting their reliability in safety-critical settings and their usefulness for broader clinical workflows. We introduce Symphony for Speech-to-Text, a medical-grade speech recognition system for real-time streaming and batch file-based clinical use. Symphony decomposes the transcription process into specialized components for recognition, formatting, and contextual correction to optimize medical term recall while producing clinically structured text in real time and adapting across use cases. Evaluations on public benchmark and medical speech datasets show that Symphony substantially outperforms state-of-the-art systems in clinical settings while matching or exceeding them in general-domain settings, suggesting robust generalization rather than overfitting. We release a clinical benchmark dataset to support reliable validation and further progress in medical speech recognition. Symphony is available through a production-grade API for live dictation, conversational transcription, and batch audio file processing.
Introduction
Speech is becoming a core interface for healthcare.
Clinicians already use speech recognition for documentation capture, electronic health record (EHR) navigation, and workflow automation, and the next generation of clinical software will increasingly rely on voice-native interaction for ambient workflows, structured data capture, and real-time assistance [Goss et al., 2019, Falcetta et al., 2023, Haberle et al., 2024]. In this setting, speech recognition is not merely a transcription utility; it is a foundational layer for both the everyday software clinicians rely on and the AI-enabled solutions healthcare builders are advancing.
This raises a higher bar than general-purpose automatic speech recognition is designed to meet. In clinical settings, systems must accurately capture rare and specialized terminology, preserve distinctions that are medically consequential, and render shorthand, acronyms, dosages, and measurements in a form that is immediately usable downstream [Hodgson et al., 2017, Zhou et al., 2018]. Errors at this level are not only cosmetic. They increase correction burden, degrade trust, and limit the usefulness of speech interfaces in real-world care delivery.
Most existing speech recognition systems are trained and evaluated as broad-domain transcription models [Radford et al., 2023]. While they have improved substantially in recent years, their core objective remains the production of plausible text from audio. That objective is insufficient for medicine, where correctness depends not only on word recognition, but also on domain-specific formatting, contextual disambiguation, and adaptation to the task at hand. A system that transcribes "fifty" correctly but fails to render a dosage, unit, acronym, or abbreviation in its clinically intended form is often still wrong in practice. Conversely, systems optimized narrowly for single-speaker medical dictation often fail to generalize to conversational clinical audio, where overlapping speech, turn-taking, disfluencies, and variable acoustic conditions make transcription substantially harder [Liesenfeld et al., 2023]. In these settings, such systems may not only miss clinically relevant content, but also produce unstable outputs, including unsupported insertions and other hallucinated text, which further limits their reliability in real-world use [Frieske and Shi, 2024].
Recent work has begun to use large language models to improve transcription outputs through rescoring, reformatting, or post-hoc correction [Yang et al., 2023, Radhakrishnan et al., 2023]. These methods show that medical speech recognition benefits from stronger language understanding, but are often introduced as loosely coupled post-processing steps rather than as an integrated system design [Hu et al., 2024]. As a result, they do not fully address the need for real-time operation, structured output, and task-specific adaptation across different clinical workflows.
Therefore, we argue that medical speech recognition should not be viewed as a single-stage transcription problem. Rather, it is better understood as a structured inference problem in which raw recognition, linguistic normalization, and contextual correction must work together to produce text that is clinically faithful and operationally useful.
We present Symphony for Speech-to-Text, combining a streaming recognition model specialized for high-precision and high-recall capture of medical terminology with support for keyterm biasing, a real-time language model for rendering structured clinical text, and a correction model that uses contextual reasoning and custom prompts to adapt outputs to different settings. The system also exposes real-time audio-quality signals that surface input audio quality problems. The result is a system designed not only to accurately transcribe speech but also to serve as an infrastructure for speech-enabled clinical workflows.
In this paper, we make the following contributions:
1. Keyterm precision and recall
We introduce a real-time speech recognition model specialized for the accurate recognition of medical terminology, spoken-punctuation symbols, and formatted entities from clinical audio.
2. Structured transcription
We introduce a real-time language model that formats acronyms, measurements, and other clinically important textual conventions during transcription.
3. Contextual correction
We present a language model for context-aware correction that can be adapted through custom prompts to different downstream use cases and documentation styles.
4. Comprehensive evaluation
We show that Symphony performs on par with or better than best-in-class systems on public benchmarks, while substantially outperforming competing systems on medical speech recognition datasets. We adopt a unified keyterm precision and recall framework that replaces the recall-only or ill-defined keyterm error rates used in prior work.
5. Dataset release
We release a new medical speech recognition dataset to support further improvement and more realistic evaluation across the field.
6. Deployment across workflows
We demonstrate a single production system that supports dictation, conversational speech, and batch audio file processing through a unified API
7. Audio quality awareness
We provide real-time audio events that expose input-quality conditions, enabling more reliable operation and better monitoring of voice-based systems.
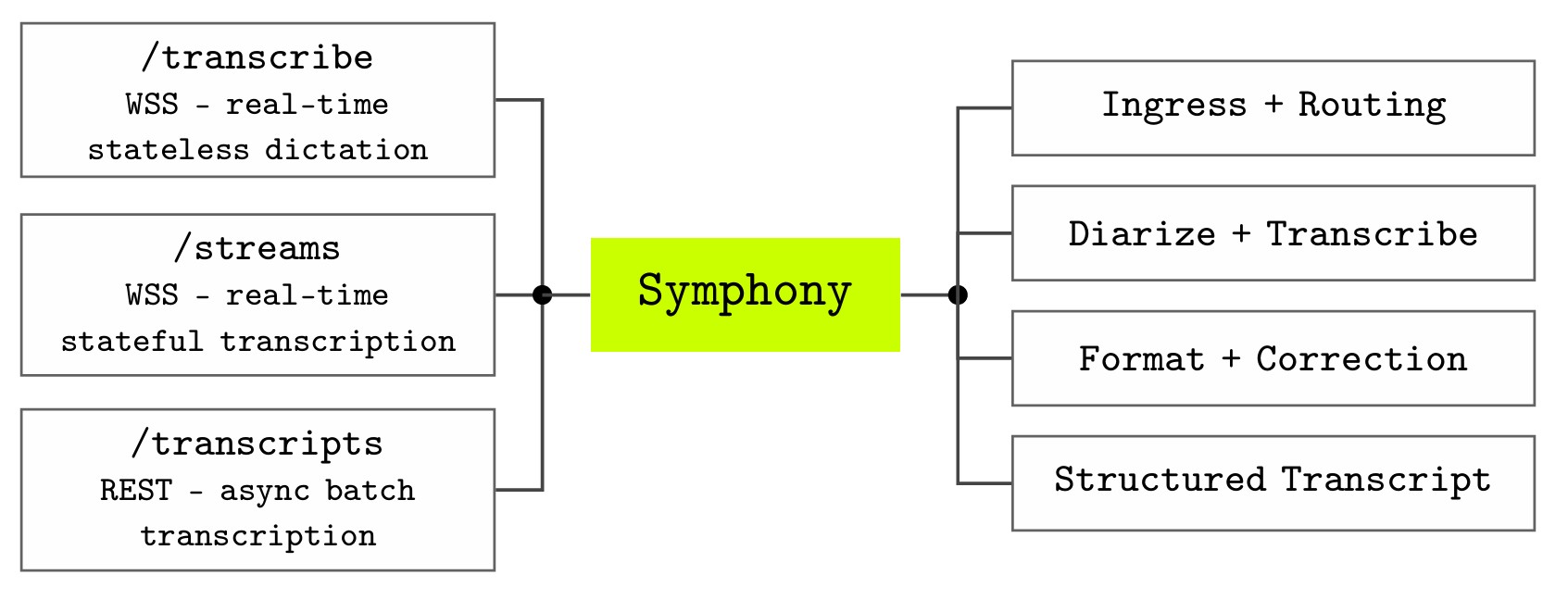
Methods
Symphony for Speech-to-Text
Symphony exposes speech recognition through three API endpoints that correspond to the main ways clinical applications interact with audio (see Figure 1).
- The
/transcribeendpoint supports real-time, stateless dictation over WebSocket Secure (WSS), making it suitable for command-and-control dictation workflows and speech-enabled user interfaces. - The
/streamsendpoint provides a real-time, stateful WSS interface for conversational transcription and clinical intelligence, where audio is associated with an ongoing interaction. - The
/transcriptsendpoint supports asynchronous transcription over REST for batch processing of pre-recorded audio files. Together, these endpoints allow the same underlying speech-to-text system to support live dictation and ambient conversations or audio-file-based workflows through different integration patterns.
Audio entering Symphony is first normalized through an ingress and routing layer. This layer abstracts over the differences between live WebSocket audio and uploaded recordings, allowing downstream components to operate on a common representation of the audio stream. In the streaming case, the system returns low-latency interim and final recognition results to support responsive user interfaces; in the batch case, uploaded recordings are processed through an asynchronous transcript creation workflow. This separation between endpoint semantics and recognition infrastructure allows Symphony to provide different product experiences while sharing a common transcription pipeline.
The central recognition stage performs medical speech recognition and, when configured, speaker diarization. The recognition model is optimized for high-precision and high-recall capture of clinical terminology, including medications, diagnoses, procedures, measurements, and abbreviations. For multi-speaker clinical conversations, diarization segments the transcript by speaker and assigns speech to distinct participants, improving readability and reviewability of conversational transcripts. In multichannel workflows, speaker attribution can instead be derived from channel configuration, which provides more predictable attribution when separate audio channels are available.
After recognition, Symphony applies formatting (/entity tagging) and contextual correction. This stage converts spoken clinical language into text that is useful for documentation and downstream workflows rather than merely preserving a verbatim transcript. Formatting handles domain-relevant surface forms such as dates, times, numbers, measurements, numeric ranges, and ordinals, all of which are frequent sources of errors in clinical speech recognition. For example, spoken measurements and numeric expressions must often be rendered in standardized textual forms to be safe and useful inclinical documentation.
Symphony also incorporates contextual reasoning and configurable prompting to adapt outputs to different clinical settings. This is important because the correct rendering of speech often depends on local context: the same acoustic signal may correspond to different abbreviations, medication names, units, or documentation conventions depending on specialty, workflow, and surrounding utterances. By separating recognition, formatting, and correction into distinct components, Symphony can improve raw transcription accuracy while also producing text that better matches the expectations of clinical applications.
In real-time deployments, the system additionally exposes audio-quality events to the client. These events allow applications to surface problems such as degraded speech quality, background noise, or long silence while the interaction is still in progress. This feedback loop is important for clinical voice interfaces because recognition quality depends not only on the model but also on microphone placement, background noise, channel configuration, and user behavior. Unlike other consumer applications, a clinical encounter is a singular event where audio lost to poor conditions is permanently gone. By making audio health visible to the application, Symphony supports interfaces that can prompt the user to correct input conditions before transcript quality is compromised or the opportunity it lost.
In addition to transcription, Symphony supports command-and-control workflows through its realtime API. The /transcribe endpoint is designed for stateless dictation and speech-enabled applications, where spoken commands can be used to control the user interface, edit text, trigger formatting operations, or support hands-free interaction. This makes the API suitable not only for converting speech into text, but also for building voice-first clinical interfaces in which speech acts as both an input modality for documentation and a control modality for interacting with electronic systems.
Overall, Symphony is designed as more than a transcription model. It is an API-level infrastructure for speech-enabled clinical workflows: endpoints define how applications submit audio, the shared pipeline performs medical recognition and speaker-aware transcription, and the post-processing layer transforms recognized speech into structured, clinically usable text and commands.
Training
We train Symphony on a mixture of publicly available speech and text-to-speech data, together with a large corpus of proprietary data collected by Corti. The training corpus spans a wide range of real-world acoustic and linguistic conditions, including medical consultations, clinical dictations, conversational speech, and everyday interactions. To improve robustness and coverage, we combine real recordings with synthetically generated examples that increase the representation of rare medical terminology, abbreviations, medications, measurements, and domain-specific phrasing. This mixture exposes the model to both natural variability in spoken language and targeted clinical edge cases, helping it generalize across speakers, accents, recording conditions, and workflow types.
Evaluation data
We evaluate Symphony on datasets that represent four complementary capabilities required for medical speech recognition:
- General clinical dictation
- Radiology dictation
- Medical terminology coverage
- General-domain robustness
Although Symphony is available across many languages, we focus our evaluation on English, German, and French. These languages provide a controlled multilingual benchmark spanning different pronunciation patterns, morphology, abbreviation conventions, and clinical documentation styles. This allows us to evaluate whether Symphony generalizes beyond English while maintaining high-quality annotations and comparable evaluation sets across systems. The language scope of the benchmark should therefore not be interpreted as the scope of the deployed system: Symphony supports a broader set of languages through the Corti API, with additional languages available upon request.
MedDictate
MedDictate is a carefully curated medical dictation dataset in English, French, and German, dictated by medical professionals, totaling nearly two hours of audio with gold-standard transcripts.
The dataset spans a broad range of clinical domains, from radiology to psychology, and is designed to reflect realistic documentation scenarios. The underlying notes were hand-crafted to include challenging clinical language, diverse dictation styles, and terminology-rich content, encompassing a broad set of unique medical terms. MedDictate therefore evaluates end-to-end dictation quality, including recognition of medical terminology, preservation of clinically relevant details, and accurate rendering of dictated clinical text.
MedTerm
MedTerm is a large-scale dataset of short medical dictations, each constructed around specialized medical terms uniformly sampled from a terminology database containing more than 100,000 terms per language.
The dataset is designed to stress-test medical vocabulary coverage across English, French, and German, with particular emphasis on rare, specialized, and safety-critical terminology that may be underrepresented in general-purpose speech recognition benchmarks. In addition to medical terms, MedTerm includes formatted entities and spoken punctuation, enabling evaluation of both domain-specific recognition and clinically important text normalization.
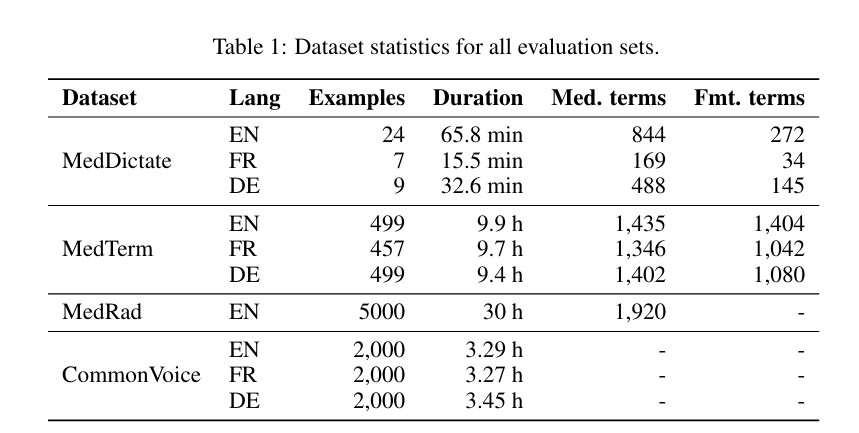
MedRad
MedRad is an English radiology dictation dataset consisting of a large set of samples.
Radiology is a key evaluation domain for medical speech recognition because it is one of the most established and high-volume uses of clinical dictation. Radiology reports are terminology-dense and frequently contain measurements, anatomical references, laterality, negation, and concise diagnostic phrasing. Errors in these elements can materially change the interpretation of a report, making radiology a strong stress test for precision, consistency, and clinical usability in real-world dictation workflows.
Common Voice
Common Voice is a large, open, community-curated speech dataset designed to expand coverage across languages, accents, and speaker populations.
Unlike more traditional English-only benchmarks, Common Voice reflects the diversity and heterogeneity of general, real-world speech contributed by volunteers. In our evaluation, we include Common Voice as a general-purpose benchmark to verify that Symphony’s medical-domain specialization does not come at the cost of regression on everyday speech recognition.
We use Common Voice for general-domain speech recognition evaluation.
FSD50K
FSD50K is a large-scale collection of everyday sound events used to evaluate robustness under realistic background-noise conditions.
We use samples from FSD50K as non-speech acoustic interference and mix them with speech at different signal-to-noise ratios. This allows us to test whether Symphony’s audio-quality events respond to degraded input conditions and whether those events correlate with downstream transcription quality. Unlike the speech datasets above, FSD50K is not used to evaluate transcription accuracy directly, but to create controlled noisy audio conditions for assessing audio-health event detection.
We use FSD50K for controlled background-noise robustness experiments.
Experiments
Evaluation metrics
Word error rate (WER) measures the edit distance between a reference transcript and a hypothesis transcript at the word level, normalized by the length of the reference. Given a reference of N words, let S, D, and I denote the minimum number of word-level substitutions, deletions, and insertions required to transform the hypothesis into the reference under Levenshtein alignment. WER is defined as:
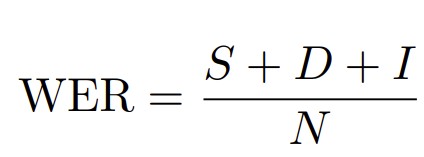
Lower WER indicates better performance. Because WER counts substitutions, deletions, and insertions relative to the reference transcript, it can exceed 100% when a system adds many extra words. WER should only be compared when the reference and model output are normalized in the same way, for example, with consistent casing, punctuation, and number formatting.
Evaluations use Corti’s open-source tooling: bewer, corti-canal, and error-align.
Keyterm precision and recall
For word categories that are clinically or functionally important, such as medical entities, formatted entities, and spoken punctuation, a single reference-based error rate is not sufficient. Such a metric primarily measures whether the expected words were recovered, but it does not separately capture whether the system introduced incorrect words. This distinction matters because false positives can be harmful: a hallucinated drug name, an incorrect dosage, or a spurious formatted value may change the clinical meaning of the transcript. For example, for spoken punctuation, a word such as“colon” or “period” may either indicate punctuation commands or appear asordinary content words, depending on context.
Let V be a keyterm vocabulary, and let A be the word-level Levenshtein alignment between reference and hypothesis used for WER. Restricting attention to termsin V:
- TP: the number of V-terms in the reference whose aligned hypothesis tokens under A correspond to the same V-term.
- FN: the number of V-terms in the reference whose aligned hypothesis tokens are missing or are not the same V-token (recall failures).
- FP: the number of 𝒱-terms in the hypothesis whose aligned reference tokens are not the same 𝒱-token (precision failures).
Precision and recall are then:
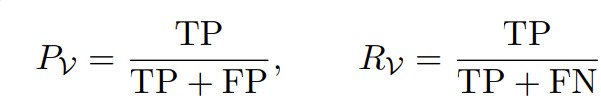
Higher is better for both. We instantiate V with three vocabularies and report the corresponding precision/recall pairs: medical entities (Pmed, Rmed), formatted entities (Pfmt, Rfmt), and spoken punctuation symbols (Ppunct, Rpunct). The disambiguation cases fall out of thedefinition: if the speaker uttered the literal word “colon” in an anatomicalcontext and the system emitted “:”, the symbol contributes an FP to Ppunct; if the symbol was intended and the system emittedthe word, that contributes an FN to Rpunct.
Reporting precision and recall separately, rather thanaggregating into F1 or a single error rate, exposes which side of thetrade-off a system fails on: a system that always emits the symbol, or thatalways inserts every drug name from its bias list, will look strong on recalland weak on precision, and we want that visible.
Keyterm biasing (rFNR, Pmed) We measure biasing effectiveness by the relative reduction in miss rate when a biasing vocabulary is provided, and monitor precision to verify that biasing does not introduce spurious detections.
The relative FNR reduction under biasing is:
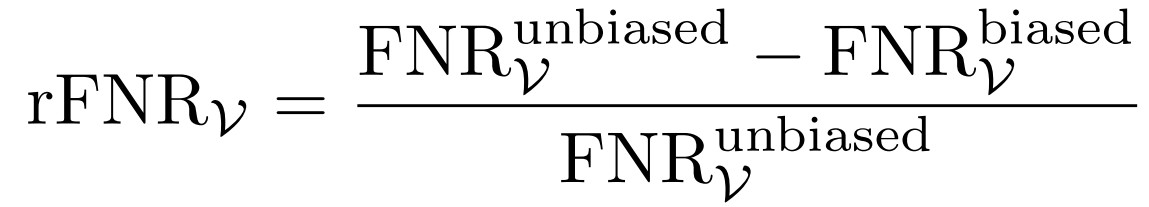
where FNRV = 1 − RV. This quantity is defined whenever the unbiased system makes at least one miss. A value of rFNR = 0.5 means biasing eliminates half of the unbiased system’s misses; because the reduction is relative, it rewards the same proportional improvement whether baseline recall is 80% or 98%. To verify that recall gains do not come at the cost ofspurious detections, we report Pmed under both unbiased andbiased conditions. Safe biasing leaves precision essentially unchanged; anotable drop in Pmedbiased relativeto Pmedunbiased wouldsignal over-aggressive biasing.
Confidence estimation
For each system, dataset, and metric, we estimate uncertainty using the percentile bootstrap. We draw S = 1000 bootstrap samples with replacement at the utterance level from the evaluation set and recompute the metric on each resample. The metric computed on the full evaluation set is used as the point estimate, and the 2.5th and 97.5th percentiles of the bootstrap distribution define the 95% confidence interval. This captures both sampling variability in the metric estimate and the sensitivity of system comparisons to the composition of the evaluation set, which is particularly important for smaller medical benchmarks.
Text normalization
Our goal is to identify the strongest overall transcription system for medical use among the systems we compare. Because accurate formatting of dosages, units, dates, and similar entities is essential in medical speech recognition, we compute all metrics against formatted reference transcripts that represent the expected output of a medical transcription system. For general-domain transcription, we apply the same principle when formattable entities are present, although such entities occur less frequently.
In our normalization pipeline, both reference and hypothesis text are passed through a deterministic normalization pipeline that strips automaticpunctuation (orthographic commas, periods, question marks, etc. inserted by the system but not spoken), expands numeric and unit tokens to their spoken word forms (e.g. “50mg” → “fifty milligrams”), expands acronyms and abbreviations to their spoken expansions, collapses repeated whitespace, and removes disfluency markers. Capitalization is preserved, so that proper nouns and other case-sensitive tokens remain distinguishable in the reference. We do not measure auto-punctuation: punctuation is only scored when it was actually spoken. Concretely, anutterance of the word “colon” in its anatomical sense is preserved as the literal token “colon” in the non-formatted reference and remains the word“colon” in the formatted reference; an utterance of “colon” as a dictation command becomes “colon” in the non-formatted reference and “:” in the formatted reference. This makes spoken-punctuation evaluation an explicit disambiguation test: a system that always emits “:” for “colon” is correct in the dictation-command case but wrong in the anatomical case, and is penalized for the latter through the precision term defined above. The same pipeline is applied identically to every system under evaluation, so that differences in surface formatting conventions across vendors do not contribute to the reported error.
Speech-to-Text Systems for Comparison
We compare Symphony against a set of widely used commercial speech-to-text systems. Our goal is to evaluate Symphony not only against general-purpose speech recognition APIs, but also against a dedicated medical dictation product that represents the current standard in many clinical documentation workflows.
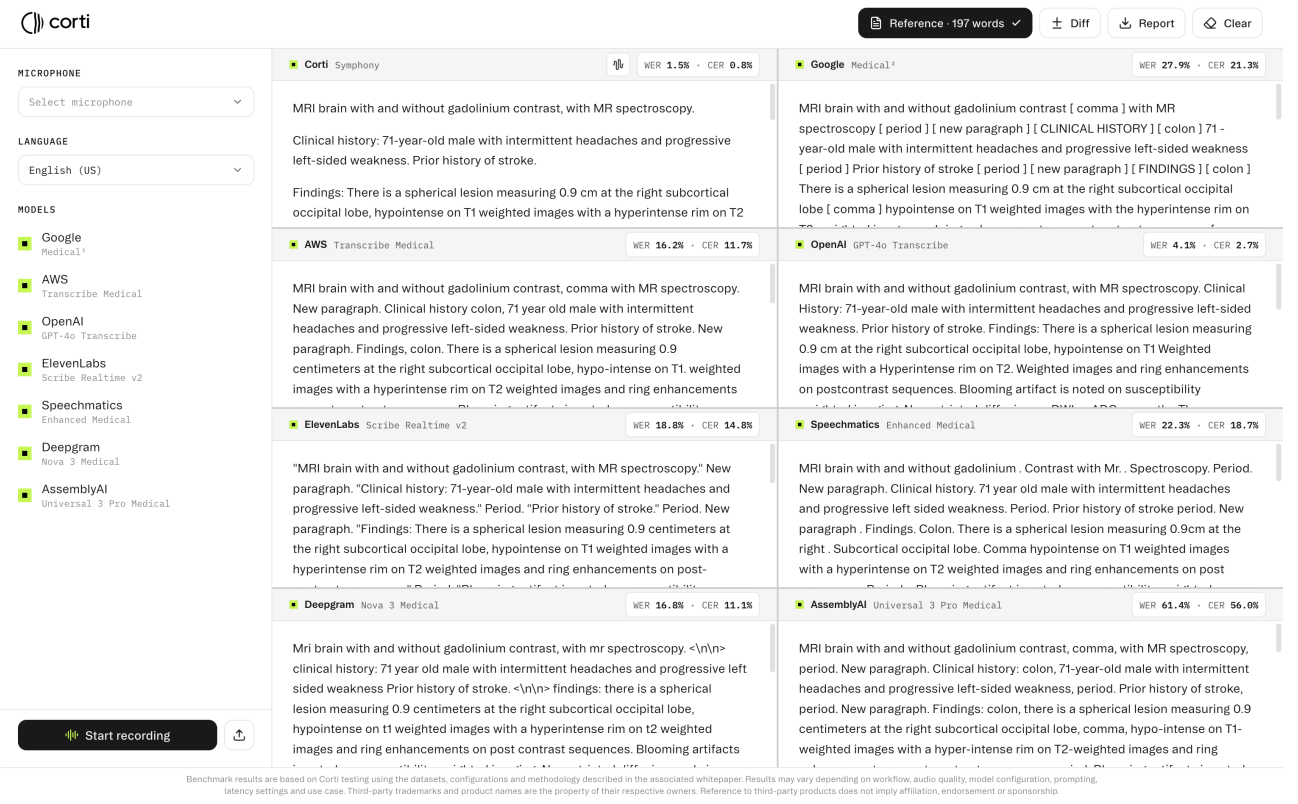
We first conducted a pre-evaluation of major cloud-based speech recognition APIs, including Deepgram, AssemblyAI, Speechmatics, OpenAI,ElevenLabs, Google Cloud, Amazon Transcribe, and Microsoft Azure (see Figure 2). These systems represent a broad cross-section of commercially available speech recognition services, including both batch and real-time APIs, and are commonly used as general-purpose transcription backends.
The pre-evaluation was used to identify the strongest general-purpose systems for a more detailed comparison. For the systems providing options for medical transcription, we chose such an option (for example, AmazonTranscribe Medical and Google Clod Speech-to-Text). Among the cloud APIs considered, ElevenLabs, Amazon Transcribe Medical, Google Cloud, and OpenAI performed best in our initial screening. We therefore selected these four systems for a full offline evaluation on our medical and general-domain benchmarks.
In the offline evaluation, OpenAI Speech-to-Text and ElevenLabs Speech-to-Text were the strongest performing general-purpose APIs overall. We consequently selected these two systems for the real-time evaluation against Symphony. This two-stage selection procedure allows us to compare Symphony against a broad set of available systems while focusing the real-time experiments on the strongest general-purpose baselines observed in batch mode.
We additionally evaluate Dragon Medical One, a dedicated medical speech recognition product for clinical dictation. Unlike the cloud APIs above, Dragon Medical One is designed specifically for clinician-facing documentation workflows and is widely used in healthcare settings. It is therefore an important comparator for evaluating whether Symphony improves not only over general-purpose speech-to-text APIs, but also over a specialized front-end dictation system deployed in real-world medical environments. Including Dragon Medical One allows us to test Symphony against both classes of relevant competitors: best-performing cloud speech APIs and an established medical dictation solution.
We also evaluate two leading open-source speech recognition architectures: Whisper and Parakeet. These models provide important reference points because they are widely used as research and deployment baselines outside proprietary cloud APIs. Whisper is a multilingual encoder-decoder model trained on large-scale weak supervision and has become a standard open-source baseline for robust general-purpose transcription [Radford et al., 2022]. Parakeet is a family of high-performance ASR models released through NVIDIA NeMo, based on modern transducer-style architectures designed for accurate and efficient speech recognition [NVIDIA Conversational AI, 2024, Sekoyan et al.,2025]. Including these systems allows us to compare Symphony not only against commercial APIs and medical dictation software, but also against strong open-source alternatives that can be self-hosted and adapted by researchers or developers.
Results
We evaluate Symphony across four complementary settings:
- Medical terminology coverage
- Realistic medical dictation
- General-domain speech recognition
- Keyterm biasing
The medical evaluations test whether systems can recognize specialized clinical vocabulary, render formatted entities, and handle spoken punctuation in dictation-style workflows. The CommonVoice evaluation serves as a general-domain control to assess whether medical specialization degrades broader speech recognition performance. Finally, the keyterm biasing experiment measures whether Symphony can safely adapt to user- or workflow-specific terminology without sacrificing precision.
Across these settings, we compare Symphony against leading open-source ASR models, commercial speech-to-text APIs, and, where applicable, a dedicated medical dictation system. We report both aggregate transcription quality through WER and clinically targeted metrics for medical terms,formatted entities, and spoken punctuation.
Real-Time on MedTerm, English only
Comparison across WER and keyterm precision/recall (PV, RV ) for medical entities (V = med), spoken-punctuation symbols (V = punct), and formatted entities (V = fmt). Higher is better for P/R metrics; lower is better for WER. All values in %. 95% confidence intervals shown below each value. Bold indicates best in each row.
Medical Terminology
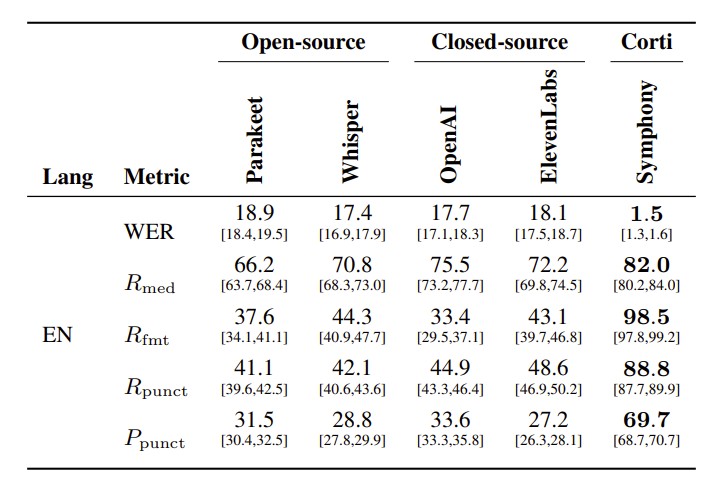
Across all MedTerm evaluations, Symphony achieves the strongest overall performance, with particularly large gains in the metrics most directly tied to medical usability.
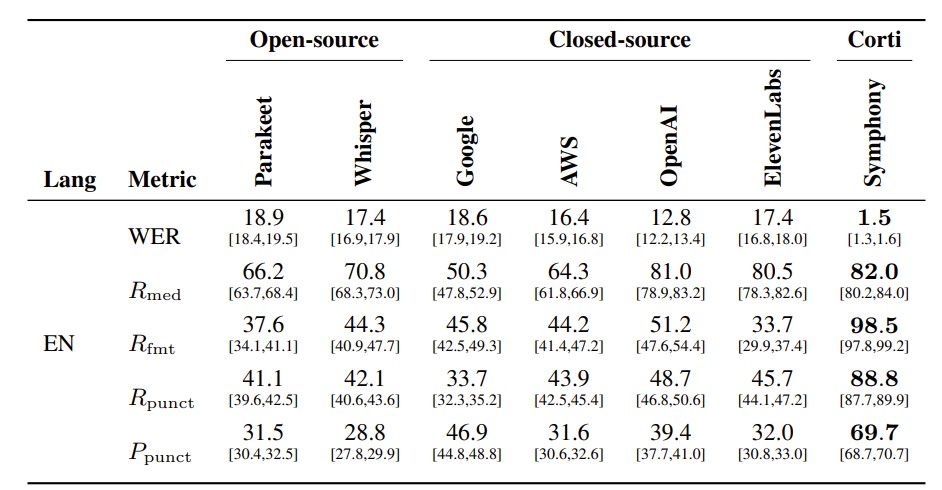
In the English real-time setting (Table 2), Symphony reduces WER to 1.4%, compared with 17.7% forOpenAI, 18.1% for ElevenLabs, 17.4% for Whisper, and 18.9% for Parakeet. Symphony also obtains the highest medical term recall, reaching 84.1%, compared with 75.5% for the strongest non-Corti system. These results indicate that Symphony substantially improves recognition of specialized medical terminology while also reducing overall transcription errors.
The largest differences appear on formatting and spoken-punctuation metrics. On English MedTerm,Symphony reaches 98.3% recall on formatted entities, while the strongest baseline reaches only 44.3% in the real-time comparison and 51.2% in the offline comparison. Similarly, Symphonyobtains 92.4% spoken-punctuation recall and 70.3% spoken-punctuation precision, substantially outperforming all baselines. This gap is important because formatted entities and spoken punctuation are central to clinical dictation: dosages, measurements, dates, and punctuation commands must be rendered correctly for transcripts to be useful in documentation workflows.
The offline comparison (Table 3) shows that these gains are not only due to comparing against weakerreal-time systems. Even when evaluating against stronger offline APIs, the real-time Symphony remains best on every metric. OpenAI is the strongest non-Corti baseline on English MedTerm, with 12.8% WER, 81.0% medical term recall, and 51.2% formatted entity recall. Symphony improves over this with 1.4% WER, 84.1% medical term recall, and 98.3% formatted entity recall. The difference is especially pronounced for formatting and spoken punctuation, suggesting that Symphony is not merely a stronger recognizer, but better aligned with the output requirements of medical dictation.
The German and French results (Table 4) show that the same pattern holds beyond English. For German, Symphony achieves 2.4% WER, compared with 13.0% for OpenAI, 16.4% for ElevenLabs,15.6% for Whisper, and 15.9% for Parakeet. Symphony also obtains the best medical term recall at 76.4%, the best formatted entity recall at 99.4%, and the best spoken-punctuation recall at 96.1%. For French, Symphony achieves 3.9% WER, compared with 10.6% for OpenAI, 16.0% for ElevenLabs,13.9% for Whisper, and 14.7% for Parakeet. It also reaches the highest medical term recall, formatted entity recall, spoken-punctuation recall, and spoken-punctuation precision.
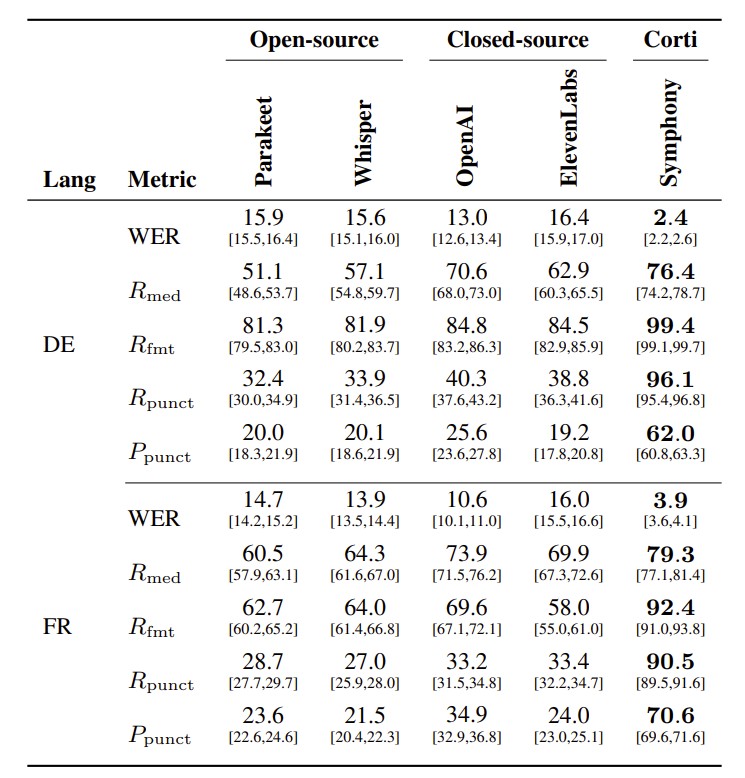
Overall, the MedTerm results demonstrate that Symphony provides large improvements over both open-source systems and leading closed-source speech-to-text APIs. The improvements are consistent across English, German, and French, and are strongest on the clinically important categories that general-purpose systems handle poorly: medical terms, formatted entities, and spoken punctuation. This supports the central design goal of Symphony: producing transcripts that are not only acoustically accurate, but also formatted and structured for real-world medical dictation workflows.
Medical Dictation
Real-Time on MedDictate, English only
Table 5 evaluates Symphony on MedDictate, a realistic English medical dictation benchmark, against both general open-source ASR models and Dragon Medical One (DMO), a front-end speech recognition system specialized for clinical dictation. This comparison is important because DMO represents a strong and widely adopted medical dictation baseline, whereas Parakeet and Whisper provide a sanity check for how far general-purpose open-source models are from meeting the requirements of this setting.
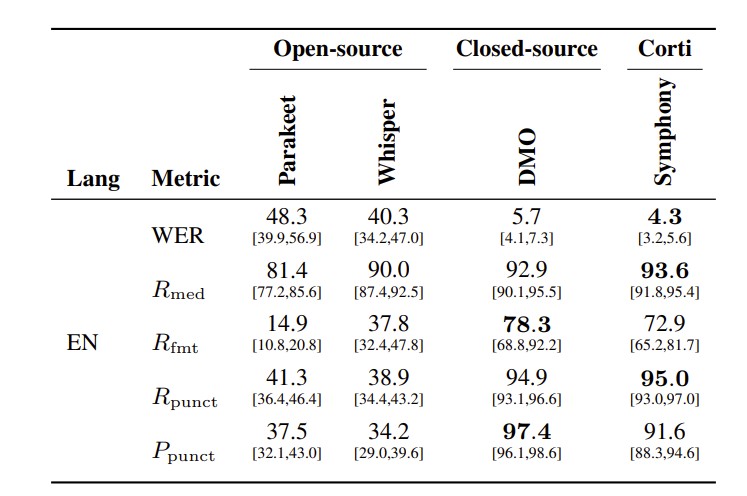
Comparison across WER and keyterm precision/recall (PV, RV ) for medical entities (V = med), spoken-punctuation symbols (V = punct), and formatted entities (V = fmt). Higher is better for P/R metrics; lower is better for WER. All values in %. 95% confidence intervals shown below each value. Bold indicates best in each row.
The open-source systems perform poorly on MedDictate. Parakeet and Whisper obtain WERs of 48.3% and 40.3%, respectively, indicating that general-purpose ASR models struggle with realistic medical dictation despite reasonable medical term recall. Their performance is especially weak on formatted entities and spoken punctuation: Parakeet reaches only 14.9% formatted entity recall, and Whisper reaches 37.8%, while both systems remain below 42% spoken-punctuation recall and below 38% spoken-punctuation precision. These results show that medical dictation is not only a recognition problem, but also requires domain-specific handling of formatting, punctuation commands, and clinically meaningful surface forms.
Compared with DMO, Symphony achieves a lower WER (4.6% vs. 5.7%), slightly higher medical term recall (93.5% vs. 92.9%), and comparable spoken-punctuation precision — reaching the performance regime of a dedicated medical dictation system while being exposed through an API designed for broader clinical workflows. DMO remains strongest on formatted entity recall and spoken-punctuation recall, reaching 78.3% and 94.9% compared with Symphony’s 74.4% and 89.0%. However, DMO’s medical-term false discovery rate is almost twice that of Symphony (1.33% vs.0.79%), evidence that its strong recall partly reflects over-aggressive vocabulary priors that insert medical terms where none were spoken. This over-specialization tendency is also visible in the qualitative comparison on conversational speech in Figure 3.
General-Domain Speech Recognition
To verify that the medical-domain gains do not come at the expense of general speech recognition quality, we evaluate all real-time systems on CommonVoice in English, German, and French. This benchmark serves as a general-domain control setting: unlike MedTerm and MedDictate, it does not specifically target clinical terminology, formatting, or dictation commands.
Real-Time on CommonVoice
Table 6 shows that Symphony remains competitive with strong general-purpose systems across allthree languages. In English, Symphony obtains the lowest WER at 11.2%, closely followed by ElevenLabs at 11.3%, also outperforming Whisper and OpenAI real-time. In German, Symphony also achieves the best WER at 6.6%, slightly ahead of OpenAI real-time at 6.7% and ElevenLabs real-time at 6.9%. In French, Symphony again obtains the lowest WER at 8.0%, outperforming Parakeet, OpenAI Realtime, ElevenLabs Realtime, and Whisper.
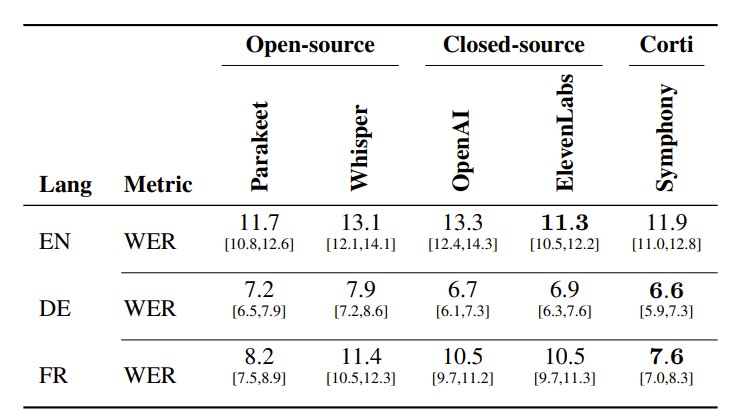
These results indicate that Symphony’s specialization formedical speech does not lead to a loss of general-domain recognition performance. Instead, Symphony remains on par with or better than leading real-time baselines on CommonVoice, while substantially outperforming the same systems on medical terminology, formatting, and dictation-oriented metrics. This supports the conclusion that Symphony’s improvements in clinical settings reflect domain-specific capability rather than overfitting to narrow medical evaluation data.
On the other hand, Google Medical ASR and DMO illustrate the risks of narrow domain specialization.In our evaluations, Google Medical reached 40.0% WER on English CommonVoice, far worse than any real-time system in Table 6 despite being offline itself, indicating poor generalization to nonclinical speech. DMO could not be systematically evaluated on CommonVoice, as it is a front-end dictation application, but as noted above, its elevated false discovery rate for medical terms on MedDictate and qualitative examples of conversational speech (Figure 3) show the same signs of over-specialization; the system inserts medical terms where none were spoken, even in medical audio.
Keyterm biasing
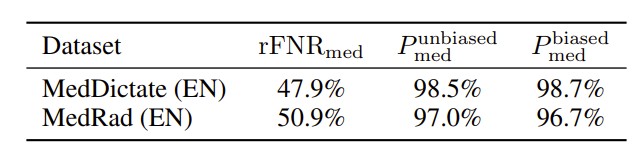
We evaluate keyterm biasing by providing Symphony with the set of medical terms present in each evaluation dataset and measuring its effect on medical term false negatives. As shown in Table 7, biasing substantially improves medical term coverage. On MedDictate, the medical term false negative rate is reduced by 47.9% relative to the unbiased baseline, while on MedRad the reduction is 50.9%. This indicates that keyterm biasing is effective for improving recognition of clinically important terminology that may otherwise be missed.

Importantly, the improvement in recall does not come at the cost of precision. Medical term precision remains essentially unchanged under biasing, increasing slightly from 98.5% to 98.7% on MedDictate and decreasing only marginally from 97.0% to 96.7% on MedRad. This suggests that Symphony can use user- or workflow-specific terminology to recover more relevant medical terms without introducing a substantial number of spurious medical entities. In clinical applications, this is critical: keyterm biasing should improve recognition of expected terminology, such as medications, procedures, or site-specific vocabulary, while avoiding hallucinated terms that could alter the clinical meaning of the transcript.
Audio quality events
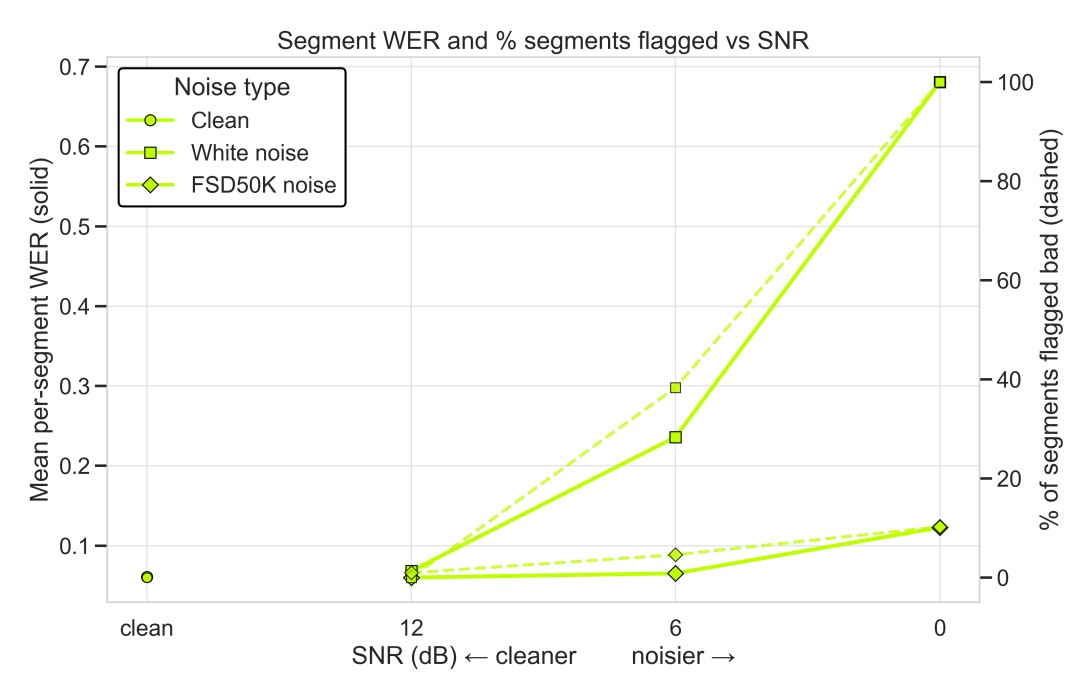
In addition to transcription accuracy, Symphony exposes real-time audio-quality events that can alert applications when input conditions are likely to degrade recognition performance. We evaluate these events by adding different types of noise to speech segments and comparing the percentage of segments flagged as low quality against the resulting per-segment WER.
Figure 4 shows that the audio-quality events track the degradation in transcription quality as the signal-to-noise ratio decreases. For clean audio, the system flags few or no segments, and WER remains low. As the audio becomes noisier, especially under white-noise corruption, both the mean per-segment WER and the percentage of flagged segments increase sharply. This indicates that the health events are not arbitrary warnings, but correlate with the conditions under which recognition quality deteriorates.
These results support the use of audio-quality events as an operational signal in real-time clinical voice interfaces. Rather than discovering input-quality problems only after a transcript has been produced, applications can surface warnings during the interaction itself, prompting users to adjust microphone placement, reduce background noise, or repeat an utterance. This makes audio-quality monitoring an important complement to model accuracy in safety-critical speech workflows.
Conclusion
We presented Symphony for Speech-to-Text, a medical-grade speech recognition system designed for real-time and offline clinicalworkflows. Symphony combines medical speech recognition, structured formatting, contextual correction, command support, audio-quality signals, and keyterm biasing within a unified API for dictation, conversational transcription, and batch processing.
Across medical terminology and medical dictation evaluations, Symphony substantially improves over strong open-source and closed-source baselines on the metrics most important for clinical use: WER, medical term recall, formatted entity recall, and spoken-punctuation handling. At the same time, results on CommonVoice show that this specialization does not come at the cost of general-domain robustness. Compared with dedicated front-end dictation systems, Symphony reaches the same performance regime while exposing a more flexible infrastructure for voice-first clinical applications.
These results support the view that medical speech recognition should not be treated as a single transcription task. Reliable clinical voice interfaces require recognition, formatting, contextual correction, and workflow adaptation to work together. Symphony demonstrates that such an integrated design can improve both transcription accuracy and clinical usability, providing a foundation for future voice-native healthcare systems.


.png)
Join our mission
We believe everyone should have access to medical expertise, no matter where they are.