

TLDR
- Symphony for Speech-to-Text is our next generation of clinical-grade STT models for developers building voice-powered healthcare software.
- It substantially outperforms general-purpose APIs (OpenAI, ElevenLabs, Whisper, Parakeet) on medical terminology, formatting, and hallucination robustness.
- It outperforms Dragon Medical One on word error rate while maintaining formatting accuracy, and is accessible via a flexible, developer-friendly API versus expensive, fixed client-side software.
- One API, streaming and batch, available in production today across English, German, French, Danish, and additional languages across the U.S. and EU.
Introducing Symphony for Speech-to-Text
Today we are launching Symphony for Speech-to-Text, our next generation of clinical-grade speech to text models for developers building voice-powered healthcare software. Benchmarked against OpenAI, Google, AWS, ElevenLabs, Whisper, and Parakeet on real clinical audio, Symphony leads on medical dictation accuracy, formatting, and hallucination robustness, and matches Dragon Medical One on word error rate. One API, streaming and batch, with global language coverage.
Voice as the interface for healthcare
Speech is the natural interface for clinical work. Clinicians already speak more than they type. The documentation layer, the EHR navigation, the ambient capture, the real-time assistance. All of it works better, or only works at all, when the software can understand spoken clinical language accurately and reliably.
The technology that exists today was not built for that job.
General-purpose speech recognition APIs are optimized for general audio. They produce plausible transcripts from podcasts, call center recordings, and meeting notes. When they encounter a clinical encounter, they fail on the terms that matter most: drug names, dosages, diagnoses, abbreviations, and spoken formatting commands. Word error rates that look reasonable on a general benchmark jump dramatically when the audio is clinical. The systems that were built specifically for clinical speech, Dragon Medical One and its predecessors, were designed for a different era. They require client software installed on the device, a vendor implementation project to embed in a product, and a static transcript output that has no path into the rest of a software system.
Healthcare product teams and developers building voice-first clinical software are caught between two bad options.
Today, we are launching Symphony for Speech-to-Text to fix that.
A structured inference problem, not a transcription task
Most speech recognition systems treat transcription as a single-pass task. Audio goes in, text comes out. The model does its best to produce plausible words in order.
That objective is insufficient for clinical use. A system that transcribes "fifty" correctly but renders a dosage as text instead of a formatted measurement is still wrong in a way that matters. A system that cannot handle spoken punctuation commands corrupts dictation workflows. A system that cannot be configured to bias toward facility-specific drug names, procedure names, or clinician identifiers will consistently miss the terms that carry the most clinical weight. And a system that produces a static text blob with no signal about audio quality leaves the pipeline blind to the conditions that are actively degrading recognition.
Symphony for Speech to Text approaches transcription as a structured inference problem. Raw recognition, formatting, and contextual correction are separated into distinct, accountable pipeline stages rather than collapsed into a single pass. The result is not just a more accurate transcript. It is a transcript that is formatted, structured, and ready for downstream agents and software systems to act on.
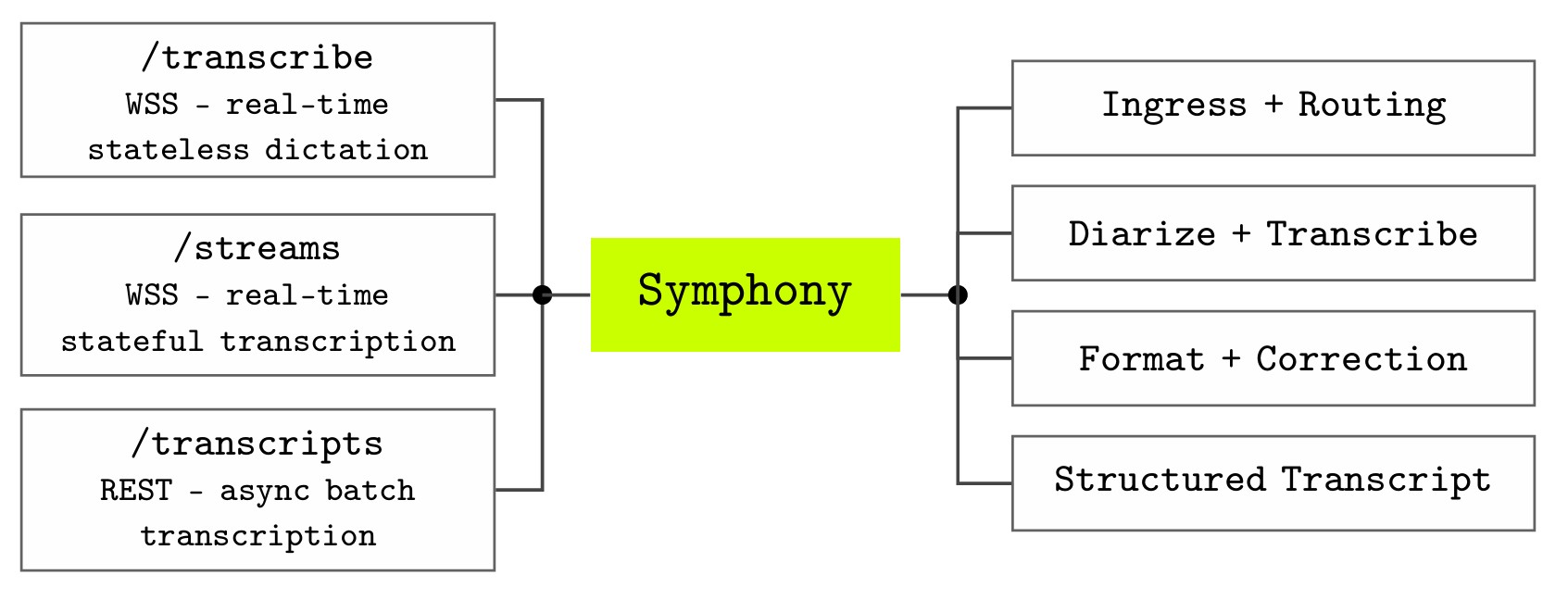
How Symphony for Speech to Text works
Symphony exposes speech recognition through three API endpoints that correspond to the main ways clinical applications interact with audio.
The /transcribe endpoint supports real-time, stateless dictation over WebSocket Secure, suitable for command-and-control dictation and speech-enabled user interfaces. The /streams endpoint provides a real-time, stateful interface for conversational transcription and clinical intelligence, where audio is associated with an ongoing interaction. The /transcripts endpoint supports asynchronous transcription over REST for batch processing of pre-recorded audio files.
All three endpoints share a common processing pipeline.
- Recognition. The first stage performs medical speech recognition optimized for high-precision and high-recall capture of clinical terminology, including medications, diagnoses, procedures, measurements, and abbreviations. For multi-speaker clinical conversations, diarization segments the transcript by speaker and assigns speech to distinct participants.
- Formatting. A real-time language model converts spoken clinical language into structured text. Dates, times, numbers, measurements, numeric ranges, ordinals, and spoken punctuation commands are rendered in the correct clinical form as audio streams in. This stage runs in real time, not as a post-processing step.
- Contextual correction. A third model applies configurable contextual reasoning to adapt outputs to the specific use case before they leave the system. The same acoustic signal may correspond to different abbreviations, medication names, or documentation conventions depending on specialty and workflow. Contextual correction handles that without requiring a separate pipeline.
Symphony also supports keyterm biasing, which allows developers to inject a custom vocabulary at inference time. Supply drug names, facility abbreviations, procedure codes, or clinician identifiers, and Symphony biases recognition toward those terms without degrading precision on terms already handled correctly.
In real-time deployments, the system additionally surfaces audio health events alongside the transcript. When input conditions are degrading, the API tells you during the encounter, not after it ends. A clinical encounter is a singular event. Audio lost to poor conditions is permanently gone.
Benchmark results
Symphony was evaluated on datasets covering medical dictation, radiology dictation, medical terminology coverage, and general-domain speech recognition across English, German, and French.
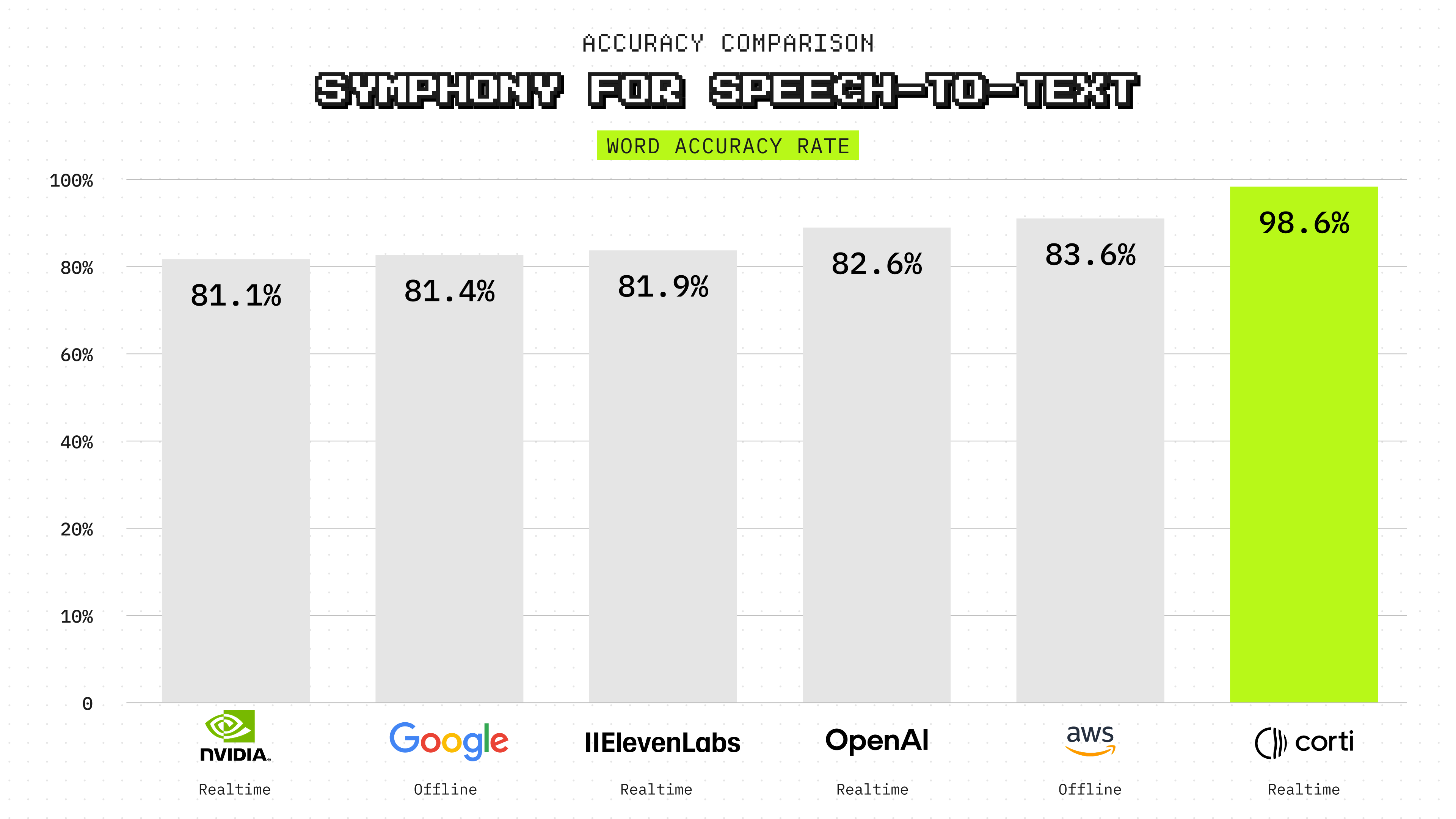
On the MedTerm benchmark, which stress-tests medical vocabulary coverage across more than 100,000 specialized clinical terms per language, Symphony achieves 1.4% word error rate in English, compared with 17.7% for OpenAI, 18.1% for ElevenLabs, 17.4% for Whisper, and 18.9% for Parakeet.
The formatting gap is the largest. Symphony achieves 98.3% recall on formatted entities, including dosages, units, dates, and measurements, while the strongest alternative reaches 44.3%. Spoken punctuation recall is 92.4%, compared with 48.6% for the best baseline. These differences reflect the architectural choice to treat formatting as a first-class pipeline stage rather than a post-hoc layer.
The same pattern holds in German and French. Symphony achieves 2.4% WER in German versus 13.0% for OpenAI. In French, 3.9% versus 10.6%. Formatted entity recall in German reaches 99.4%, compared with 84.8% for the best alternative. The gains are not specific to English.
On MedDictate, a curated benchmark of realistic medical dictation, Symphony achieves 4.6% WER compared with 5.7% for Dragon Medical One, and leads on medical term recall (93.5% versus 92.9%). Dragon Medical One retains leads on formatted entity recall (78.3% versus 74.4%) and spoken punctuation recall (94.9% versus 89.0%), reflecting its optimization for single-speaker front-end dictation. Symphony's overall WER and medical term recall are stronger.
.png)
To verify that clinical specialization does not come at the cost of general robustness, Symphony was also evaluated on CommonVoice across all three languages. Symphony is competitive with or better than leading real-time APIs on every language, confirming that the gains on clinical speech reflect domain-specific capability rather than narrow overfitting.
Keyterm biasing reduces the false-negative rate on medical terms by approximately 50% relative to the unbiased baseline on both MedDictate and MedRad, with precision essentially unchanged. Biasing recovers missed terms without introducing spurious ones.
Available now
Symphony for Speech to Text is available in production today through the Corti API and Console across English, German, French, Danish, and additional languages. Enterprise and sovereign cloud deployments are available for organizations handling protected health information.
For the companies building what comes next
Clinical voice has been a promise that has not delivered for decades. The limitation was not the idea. It was the accuracy and reliability of the underlying speech layer, and the architecture of the tools that existed.
A clinician who cannot trust that a spoken dosage will be captured correctly will stop using voice. A developer who has to build a post-processing pipeline to fix formatting errors, and then rebuild it every time the underlying model changes, is not building clinical software. They are maintaining a fragile integration.
Symphony for Speech to Text is infrastructure. One API. Real-time or batch. The clinical formatting, the spoken punctuation, the keyterm biasing, the audio health signals, and the structured outputs are all part of the API response. No separate pipeline. No client software. No vendor project.
The companies building the next generation of clinical documentation tools, ambient scribes, EHR voice interfaces, telemedicine platforms, and clinical AI systems should not have to solve medical speech recognition from scratch. They should make one API call.


.png)
Join our mission
We believe everyone should have access to medical expertise, no matter where they are.