

Medical coding is how healthcare structures itself. Every clinical encounter, every diagnosis, every procedure gets translated into standardized codes that determine whether a hospital gets paid, how much, and for what. Those same codes power epidemiological research, public health surveillance, and the resource allocation decisions that health systems depend on.
It is also where the system breaks down.
Healthcare organizations spend billions annually on manual coding and outsourced RCM services precisely because existing approaches have never solved the core problem. The tools that exist today were built to match, not to reason. They scan a clinical note, surface everything that looks like a diagnosis, and hand the list back to a human to sort out.
- Claim denial rates hit nearly 12% in 2024 and are still rising.
- The US is short 30% of the certified coders it needs.
- Every October, when coding systems update, the tools that teams rely on require re-engineering and revalidation before they work reliably again.
Today, we are launching Symphony for Medical Coding to fix that.
A reasoning problem, not a labeling problem
Most AI systems treat medical coding as a prediction problem. Given a clinical note, predict the most likely codes. Train a model on annotated examples. Ship it.
The problem is that coding is not a prediction problem. It is a reasoning problem. A trained coder does not ask "what codes appeared in similar notes in my training data." They ask what conditions are present, which of those conditions are relevant to this encounter, what the coding guidelines say should and should not be coded, and whether the documentation supports coding at the required level of specificity. That is domain reasoning, and it requires understanding of clinical context, coding logic, and their relationship simultaneously.
No training-dependent model solves this. The model learns the mistakes embedded in its training data. When human coders systematically undercode secondary diagnoses, which our research across 1.8 million patients confirmed they do, a trained model learns to undercode too. The ceiling is the data.
Symphony for Medical Coding is built differently. It encodes the rules of coding directly into the architecture and uses a multi-agent workflow to reason over those rules against the clinical text. Instead of asking what is likely, it asks what is correct.
Built on the largest medical coding study of its kind
The foundation for Symphony for Medical Coding is Code Like Humans (CLH), a multi-agent framework accepted to EMNLP 2025, one of machine learning's top conferences. CLH was developed through the largest medical coding study to date, conducted on 5.8 million electronic health records from 1.8 million patients.
That research did not just produce a better model. It surfaced something more important: a fundamental problem with training-dependent approaches to coding. When we examined cases where our model disagreed with human coders, manual validation showed the model was correct 76-86% of the time. The humans had missed the diagnoses, not the model. For hypertension alone, the model identified 25,529 additional cases in a single test set that human coders had not coded.
The implications extend far beyond a benchmark number. Systematic undercoding of secondary diagnoses distorts the data that policymakers rely on for public health surveillance, research, and resource allocation. The WHO has documented this pattern globally for decades. Conditions that go unrecorded cannot be monitored, studied, or acted on. The codes that are most often missed are frequently the ones that matter most.
Symphony for Medical Coding is built on this research foundation.
How Symphony for Medical Coding works
Send a clinical note. Get back structured code predictions with source evidence and justification for every result.
Under the hood, Symphony for Medical Coding runs a four-stage agentic reasoning workflow on every request.
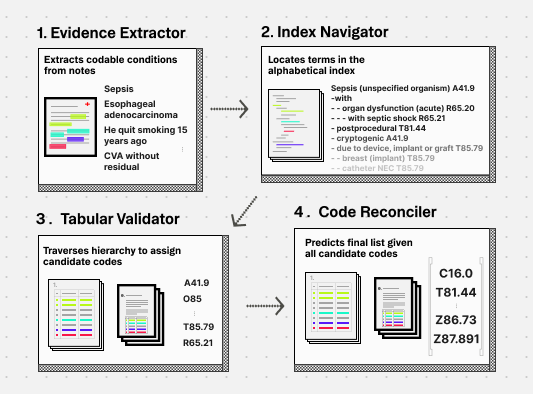
1. Identify what should be coded.
First, the model reads the clinical note and applies healthcare-specific coding rules to determine which conditions should be coded and which should not. Not everything in a note belongs on the claim. A condition mentioned in a patient's family history does not get coded. A diagnosis that was ruled out does not get coded. A historical condition no longer being managed does not get coded. The model knows the difference, because the rules are native to the architecture, not bolted on as a post-processing filter.
2. Search the index to surface candidate codes.
For each identified condition, the model queries the ICD-10 alphabetical index to locate the relevant main term and all associated sub-entries. This generates the full candidate code set, including specificity variations and combination codes, before tabular validation. The model follows the same structured lookup sequence a trained coder would use, surfacing options that a flat search would miss.
3. Traverse the hierarchy to assign the most specific code.
Second, for each identified condition, the model traverses the coding hierarchy iteratively, rewriting queries until results meet a quality threshold, then selects the most specific appropriate code available.
4. Return auditable, structured output.
Third, the model returns the primary code, ranked alternatives, the exact source text from the note that triggered the prediction, and a written justification for why the code was included or excluded. Every prediction is auditable at the prediction level.
Beyond standalone coding, Symphony's structured intermediate outputs make it a natural coordination layer within larger clinical AI systems. Downstream agents handling validation, compliance checking, and CDI can operate directly on Symphony's evidence and candidate codes rather than reasoning over raw clinical text from scratch. Symphony is available not only as an API endpoint but as an MCP that plugs directly into multi-agent systems via Corti's Agents Library.
One API call. No implementation project. No training data to source. No model to maintain.
Benchmark results outperforming OpenAI and Anthropic by over 25%
Symphony for Medical Coding was evaluated across five datasets spanning inpatient, outpatient, emergency department, and subspecialty settings across both the US and UK, making it the most comprehensive evaluation of an automated coding system to date.
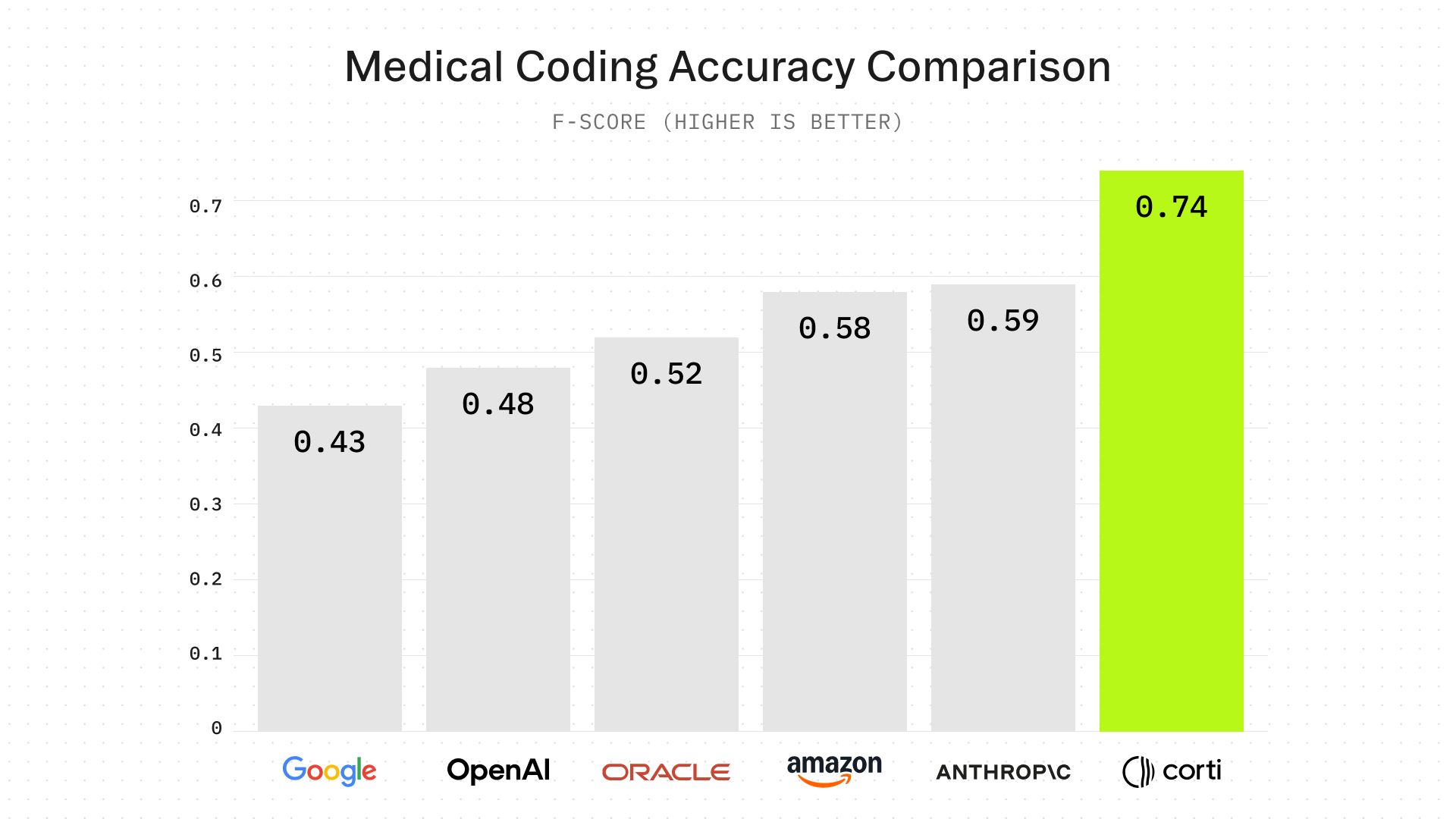
On the ACI-Note benchmark, Symphony achieves an F1 score of 74%, compared to 52% for MedDCR, the strongest workflow-based system developed by Oracle Health and AI on GPT, and 58% for the best fine-tuned model developed by the AWS AI team on the Anthropic Claude model family. On MDACE, Symphony achieves 58% F1, again leading all prior approaches.
The real-world results are more meaningful than the benchmarks. On ambulatory data from a large US provider system covering 2.25 million clinical notes, Symphony achieves 65.2% F1 compared to 58.8% for the next-best system. On emergency department data covering 563,000 clinical notes, among the most demanding coding environments due to fragmented, symptom-driven documentation produced under time pressure, Symphony achieves 43.1% F1 compared to 39.8% for GPT with tools. On procedure coding using ICD-10-PCS, Symphony achieves an F1 of 37.3% compared to 30.0% for the next-best model, maintaining the same precision-recall balance that distinguishes it on diagnosis coding.
It is also worth noting that several general-purpose models could not be evaluated on real-world clinical data at all due to HIPAA compliance constraints. Symphony is available in enterprise and sovereign cloud deployments for organizations handling protected health information.
We benchmarked on ICD-10-CM first because it is the hardest coding system in the world. With more than 70,000 codes, complex inpatient and outpatient rule differentiation, and the most established AI competition, it is the hardest version of the problem. Winning there by this margin is the floor, not the ceiling.
"Most AI systems fall short in medical coding because they treat it as labeling, not reasoning. Correct coding depends on evidence, context, hierarchy, and guideline interpretation. We built Symphony for Medical Coding to follow the same decision process expert coders use, and that is why the performance gap is so meaningful." — Lars Maaløe, CTO and co-founder, Corti
Available now across the US and Europe
Symphony for Medical Coding is production-ready today on ICD-10-CM, ICD-10-UK, ICD-10-International, ICD-10-PCS, and CPT, covering the majority of US and international clinical and billing workflows.

Because the architecture reasons from codified logic rather than patterns learned from training data, it does not require separate model builds or local annotated datasets to support new coding systems. Country-specific variants for the UK, Germany, France, Denmark, and Sweden, alongside SNOMED CT across those markets, are coming in subsequent releases. We started on the hardest system. The performance gap is expected to be larger in each system we add, not smaller.
Symphony for Medical Coding is available now through the Corti API and Console. It integrates directly with the Corti Agentic Framework and supports both A2A and MCP standards. Enterprise and sovereign cloud deployments are available.
For the companies building what comes next
Medical coding has been treated as a back-office cost center for decades. It is not. It is the data layer that healthcare runs on. Getting it right changes what health systems can see, decide, and build.
Symphony for Medical Coding is infrastructure. It is built for the developers, product teams, and healthcare software companies embedding coding into clinical documentation tools, ambient scribes, RCM platforms, prior authorization workflows, CDI systems, and EHRs. The companies building the next generation of healthcare software should not have to train a model, maintain a coding pipeline, or hire a team of coders to review the output. They should make one API call.



Join our mission
We believe everyone should have access to medical expertise, no matter where they are.