The documentation-to-billing workflow: connecting clinical notes, coding, and claims
From scribe to claim: the full documentation to billing workflow
Clinical documentation and medical billing are treated as separate problems in most healthcare organizations. One team captures the encounter while a different team codes it. A third team submits and manages the claim. That handoff structure is not accidental; it reflects how healthcare workflows developed over decades of paper-based processes and siloed software systems.
What it also reflects is a process that was never designed for automation. And the gaps between those handoffs are where revenue leaks quietly and consistently.
The workflow as it exists today
A standard documentation-to-billing cycle moves through roughly five stages.
The clinician sees the patient and documents the encounter. In traditional settings, this means dictating or typing a note after the fact. In modern settings, an ambient scribe captures the conversation in real time and generates a structured note automatically.
That note then enters a coding queue. A certified coder reviews the documentation, identifies the relevant diagnoses and procedures, applies the applicable guidelines for the care setting, and assigns ICD-10 and CPT codes.
The coded claim is reviewed before submission, either by a coding supervisor or an automated pre-submission scrubber that checks for obvious errors against payer rules.
Once submitted, the claim is processed by the payer. If it clears, payment follows. If the payer denies it, the claim enters a denial management workflow: research, correction, appeal, resubmission.
At each of these transitions, there are delays. There is information loss. There is variability introduced by whoever touches the chart next.
Where the process loses revenue
The documentation stage is where the most downstream damage originates. A note that is ambiguous, incomplete, or inconsistently structured forces coders to make judgment calls about what the clinician meant. Conservative coders leave out what is only implied. That conservatism, applied across thousands of encounters, adds up to chronic undercoding that never appears as a denial. It simply disappears.
The coding stage introduces its own variability. Coding guidelines are complex and context-dependent. Two coders reviewing the same note can produce legitimately different code sets. That inconsistency creates compliance exposure and makes quality auditing expensive because there is no single defensible interpretation on record.
The submission and denial stage is where the financial damage becomes visible. A 2026 survey from Fierce Healthcare found that most RCM teams now spend between 51 and 75 hours per week on denial-related work, and nearly half reported losing between 3% and 4% of net patient revenue to denials, underpayments, and missed timely filing windows. A meaningful share of those denied claims are never resubmitted.
What a connected workflow looks like
The ambient scribe already does the hardest part of closing this loop. It captures the encounter in real time, extracts clinical facts, and produces structured documentation. The clinical context is right there, while the encounter is still fresh.
Connecting that output directly to a coding step, rather than routing it through a separate queue days later, changes the economics of the whole process.
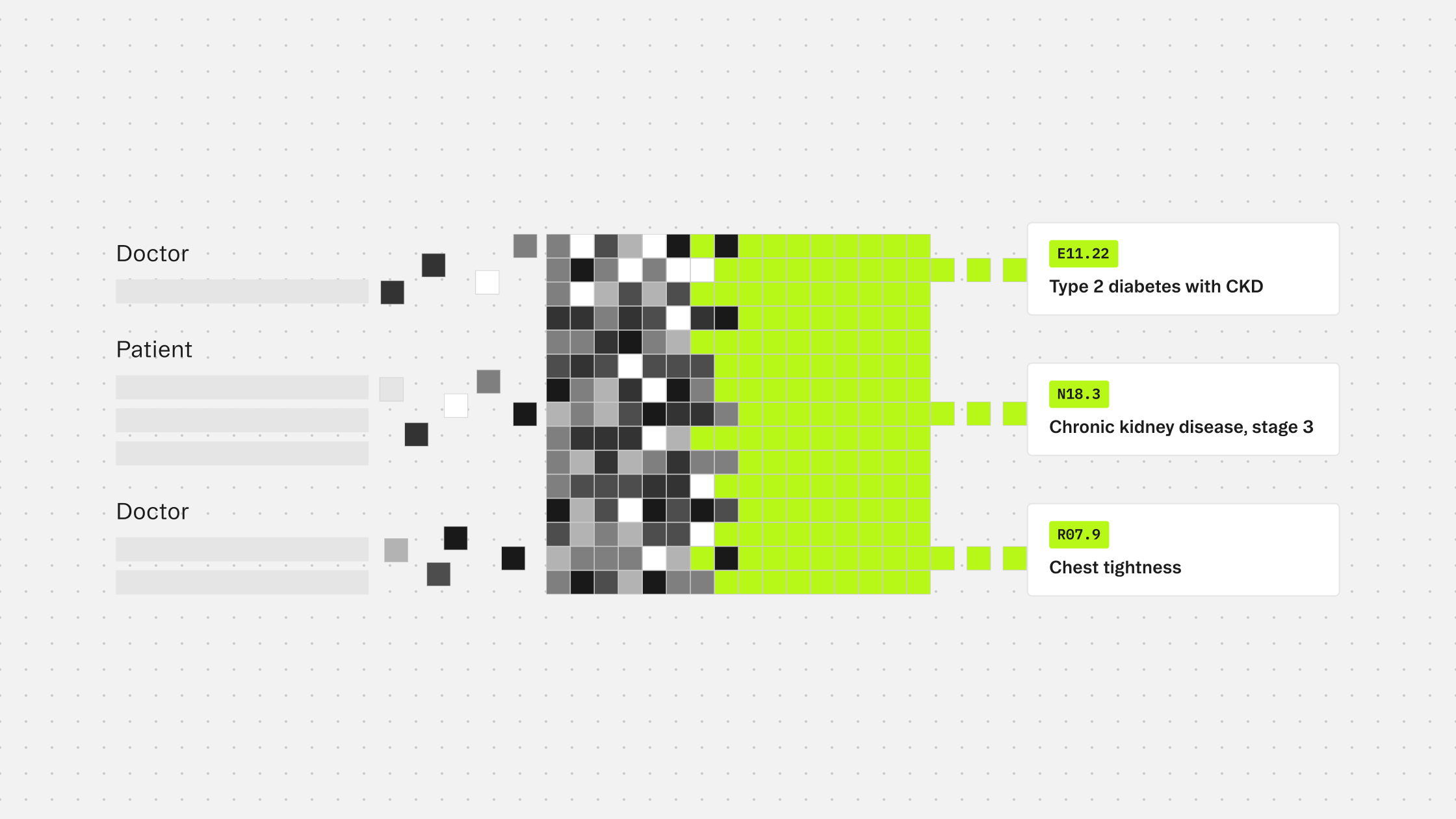
When coding runs immediately after documentation, the note is complete and unambiguous as possible. Evidence linking each code to the exact clinical language that generated it is traceable without reconstruction. The coder or reviewer receives a pre-coded chart with source evidence already attached, rather than starting from scratch.
For teams building on Corti, this connection is a single API call. The scribe produces a document. That document is passed to the /tools/coding/ endpoint as context. The response returns structured code predictions, evidence spans pointing back to the source text, and a clear distinction between conditions that should be coded and those that should not under the applicable guidelines.
Closing the loop on the claim
A documentation-to-billing workflow that is genuinely connected does more than speed up the coding step. It changes what the submitted claim looks like.
Every code arrives with source evidence. Every exclusion decision has a rationale. The output is auditable at the claim level before it is submitted, rather than after a payer challenges it.
That is what lowers denial rates in a durable way. Not faster coding, but more defensible coding, grounded in the clinical record at the point where documentation is most complete.
For builders, the architecture is straightforward: scribe output feeds coding input, coding output feeds claim preparation, and the evidence chain runs continuously from the clinician's words to the submitted bill. The workflow is connected. The revenue is recovered.
More guides to explore


Build faster. Ship safer. Scale smarter.
Get started with healthcare-native APIs built to power real clinical workflows.