How to evaluate medical speech-to-text (ASR): WER, CER, and clinical benchmarks

Automatic speech recognition (ASR) has become a foundational component in healthcare software, powering dictation tools, ambient documentation systems, and post-call transcription pipelines. Choosing the right ASR model for a clinical application is not straightforward: accuracy varies significantly across vendors, and the metrics used to compare them require some understanding to interpret correctly. This guide explains the core evaluation methodology, what the standard metrics measure, and how to conduct a meaningful comparison.
Understanding Word Error Rate
Word Error Rate (WER) is the standard benchmark metric for ASR systems. It measures the proportion of words in the hypothesis (the transcript the model produces) that differ from the reference (the ground-truth transcript). WER is computed using the minimum edit distance between the two sequences, counting three types of errors: substitutions (a wrong word), deletions (a word that was spoken but not transcribed), and insertions (a word that appears in the transcript but was not spoken).
The formula is:
WER = (Substitutions + Deletions + Insertions) / Total words in reference
Its complement, the Word Accuracy Rate (sometimes called just word accuracy or speech accuracy), is simply 100% minus WER. A model with a WER of 1.4% has a word accuracy of 98.6%. The two figures describe the same measurement; word accuracy is often the more intuitive number to communicate to clinical stakeholders, while WER is more commonly reported in technical benchmarks and research literature.
A WER of 0% means the transcript is a perfect match to the reference. As a rough reference point, WER above 20-30% in a clinical context tends to indicate a level of errors that will require meaningful manual correction, though the acceptable threshold depends heavily on the workflow and how the transcript is used downstream. In practice, even small differences in WER have a disproportionate impact on clinical utility, because errors in healthcare transcription often land on the most critical words: drug names, dosages, anatomical terms, and negations (for example, "denies" versus "has").
Understanding Character Error Rate
Character Error Rate (CER) applies the same edit-distance methodology at the character level rather than the word level. CER is particularly useful for evaluating systems in languages where word boundaries are ambiguous or for catching partial-word errors that WER would fully penalize. In English-language clinical transcription, CER is a complementary metric: a model with a low WER but a higher CER relative to WER suggests it is getting the right words in the wrong form (for example, spelling or capitalization errors), while a higher WER with a proportionally lower CER indicates the model is close on the character sequence but fragmenting or merging words incorrectly.
The formula mirrors WER:
CER = (Character substitutions + deletions + insertions) / Total characters in reference
Why general ASR metrics are insufficient for clinical use
Standard WER is computed over the full transcript. In a general-purpose context, common words dominate the word count, so a model can achieve an apparently low WER while performing poorly on the low-frequency but high-stakes terms that define clinical accuracy. A model that transcribes "the patient is a 45-year-old male" perfectly but renders "diaphoresis" as "diarrhea" or omits "denies syncope" will show a modest WER, yet produce a transcript that is clinically unreliable.
For this reason, clinical ASR evaluation may benefit from looking at domain-specific term accuracy in addition to overall WER, particularly where the application handles specialized terminology. This includes assessing performance on drug names, anatomical terminology, specialty-specific language, and diagnostic codes. A model validated against a large medical lexicon will tend to outperform a general-purpose model on these terms even if their headline WER figures are similar on non-medical speech.
One way to isolate this is through Medical Term Recall (MTR), a metric that evaluates recognition accuracy specifically against a defined list of clinical terms. Rather than averaging performance across the full transcript, MTR measures how many terms from a domain-specific vocabulary list were correctly recognized. Passing a curated term list covering the drug names, anatomical terms, and specialty phrases relevant to your use case gives a targeted accuracy signal that overall WER cannot provide.
One tool designed to address alignment challenges specifically is ErrorAlign, an open-source text-to-text alignment algorithm developed by Corti for speech recognition error analysis. Standard WER computation assumes a clean alignment between hypothesis and reference, but real clinical transcripts often contain formatting differences, reordering, or partial matches that naive alignment handles poorly. ErrorAlign improves the alignment step itself, which produces more accurate and interpretable error counts. It underpins Corti Canal (described below) and is available as a standalone library for teams that want to integrate better alignment into their own evaluation pipelines.
For teams that want a ready-made command-line evaluation tool, Corti Canal packages this alignment and scoring logic into a single utility. Canal measures how well a speech-to-text model is performing against a reference transcript and is available via PyPI and is also available via GitHub. It is a practical starting point for anyone building a repeatable evaluation workflow without having to assemble the scoring logic from scratch.
The role of a reference script
ASR evaluation generally relies on a reference transcript: a verbatim, ground-truth record of what was actually said. Without a reference, you can observe differences between model outputs but it becomes difficult to determine which output is correct.
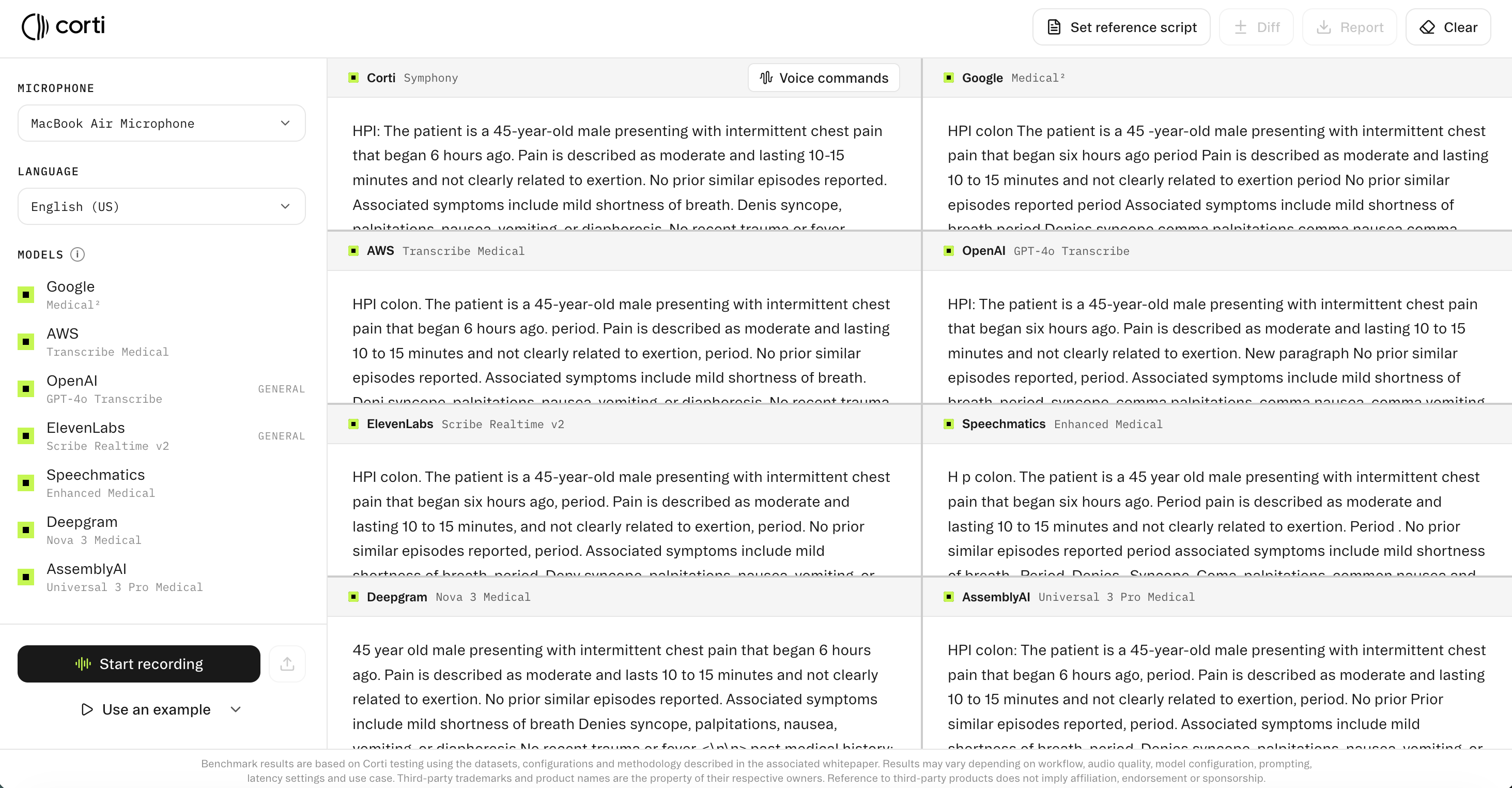
You can try this tool out at: https://www.corti.ai/compare/speech-to-text.
Once a reference script is provided, the evaluation framework becomes quantitative. Each model's output is aligned to the reference, errors are classified as substitutions, deletions, or insertions, and WER and CER are computed per model. This transforms a qualitative comparison into a structured benchmark.
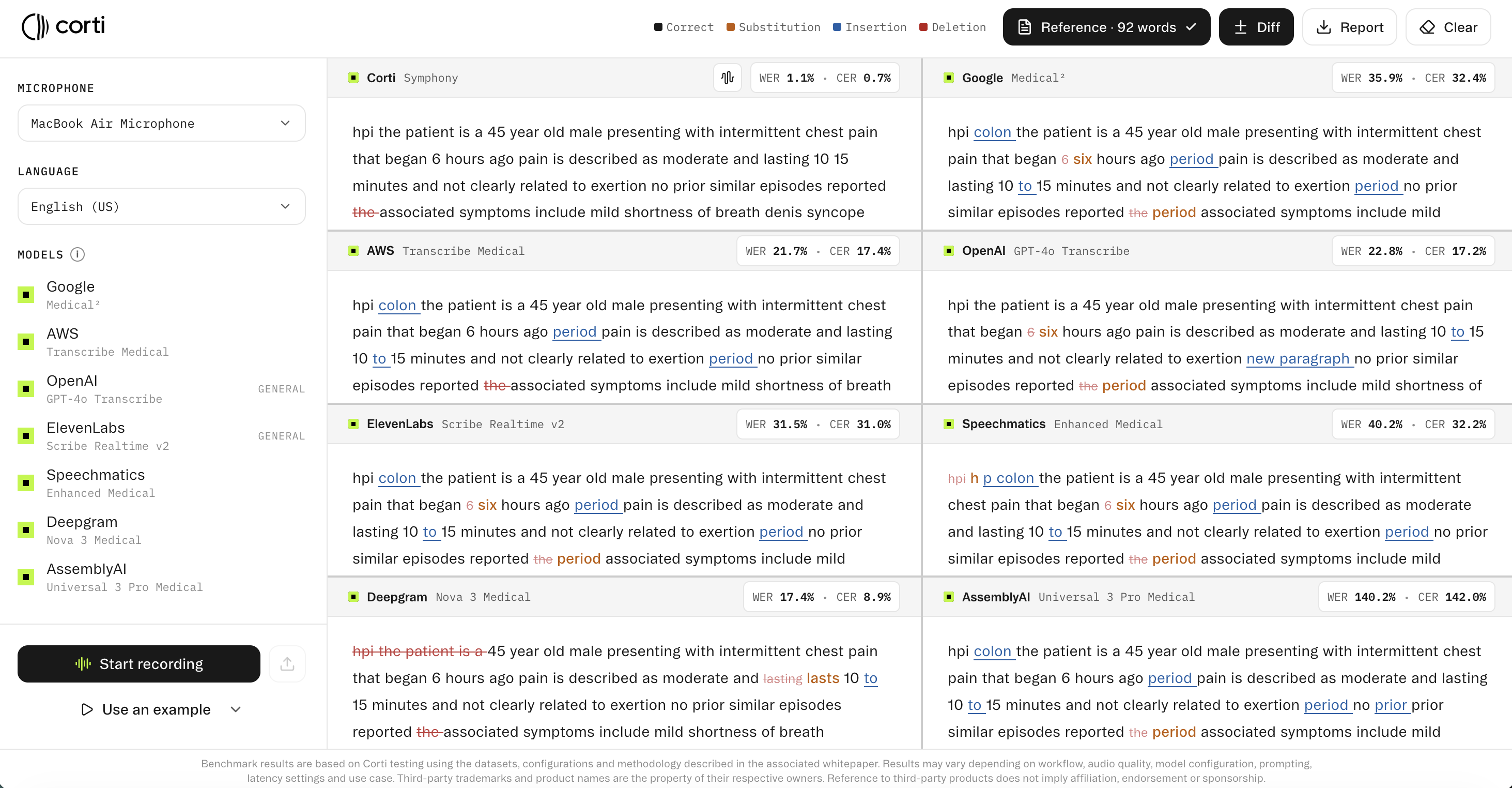
Note that when constructing a reference script for evaluation, it should be a true verbatim transcript of the audio, including disfluencies if those are relevant to your application, or a clean verbatim version if the system is expected to perform light normalization. The choice of reference standard should be consistent across all models being compared.
Conducting a comparative evaluation
One structured approach to ASR evaluation for a clinical use case involves the following steps:
- Collect representative audio samples from the actual deployment environment. Audio recorded in a quiet lab with a high-quality microphone does not represent real-world clinical conditions. Samples should reflect the range of speakers, accents, microphone types, background noise levels, and clinical specialties your application will encounter.
- Produce verified reference transcripts for each sample. This requires a human transcriptionist familiar with clinical language to produce the ground truth. The reference should be consistent in formatting choices (how numbers, dates, and abbreviations are rendered) so that formatting differences do not inflate error counts.
- Submit the same audio to each model and collect the raw transcripts. Run WER and CER calculations for each model against the reference. Analyze errors by category: substitution errors on medical terminology are more consequential than insertion errors on filler words.
- Consider secondary factors alongside accuracy: latency (how quickly interim and final results are returned), diarization quality (whether speakers are correctly separated), language coverage, and whether the system supports custom vocabulary for domain-specific terms your application uses frequently.
One practical finding worth noting: the majority of transcription quality complaints do not require a model update to resolve. Audio quality problems and integration errors (low bit rate, audio chunking issues, misconfigured API requests) account for a large share of reported issues, as do misaligned evaluations where the reference text does not match the formatting configuration or the gold transcript does not match the actual audio content. Checking these factors before concluding a model is underperforming can save significant time and avoid incorrect vendor comparisons. If you run into unexpected results during your evaluation with Corti, we encourage you to submit any issues via Corti's feedback form. Real-world cases directly inform how our team prioritizes improvements.
A note on normalization
Before WER and CER are computed, both the reference and hypothesis transcripts are typically normalized. Basic normalization includes lowercasing, removing punctuation, and stripping diacritics. The purpose is to prevent formatting differences from inflating error counts: a model that produces "Dr. Smith" versus a reference that reads "dr smith" should not be penalized for a substitution error when the underlying recognition is correct.
Normalization is most useful when applied consistently to both the reference and all model outputs being compared. Applying it to one but not the other can produce misleading comparisons. If your application requires specific formatting output (for example, capitalized drug names or numeric representations of measurements), evaluate with normalization disabled on a secondary pass to assess formatting accuracy separately from recognition accuracy.
One practical consideration: if you are comparing models that apply their own internal formatting (dates as "10/05" versus "October 5th", dosages as "10mg" versus "10 milligrams"), normalization will mask those differences. For clinical applications where output formatting feeds directly into a downstream system, running both a normalized evaluation (for recognition accuracy) and an unnormalized evaluation (for formatting fidelity) gives a more complete picture.
Interpreting results in context
WER and CER are averages over the full transcript. A model with a WER of 1.1% and CER of 0.7% on a given sample is performing with near-perfect accuracy on that input. A model with WER of 35.9% and CER of 32.4% on the same input is likely to require correction. The gap between these figures reflects not only model architecture but also whether the model was trained specifically on clinical speech data.
It is also worth noting that published benchmark results are produced under specific conditions: defined datasets, audio quality levels, and configurations. Results on your data may differ. The most reliable evaluation is one conducted on audio that closely matches your actual deployment conditions, with reference transcripts produced to a consistent standard.
Summary
Effective ASR evaluation for clinical applications tends to go beyond published WER figures alone. Using representative audio, verified reference transcripts, and a consistent methodology for computing WER and CER gives a more reliable picture of real-world performance. Weighting clinical terminology errors appropriately in that analysis, given that low-frequency medical terms carry high clinical significance, is one approach teams use to get a more complete view. Side-by-side comparison tools that apply a reference script and compute per-model metrics can help reduce subjectivity in the process, making it more practical to benchmark multiple systems before committing to an integration.
Effective ASR evaluation for clinical applications goes beyond published WER figures. Representative audio, verified reference transcripts, and a consistent scoring methodology give a far more reliable picture of real-world performance than vendor benchmarks alone. Because low-frequency medical terms carry outsized clinical significance, weighting terminology errors appropriately is one of the most important adjustments a team can make to get a complete view. Side-by-side comparison tools that apply a reference script and compute per-model metrics remove subjectivity from the process, making it practical to benchmark multiple systems before committing to an integration. The most reliable path to a confident integration decision is evaluation on your own data, with your own clinical vocabulary, under your own deployment conditions. Corti's Speech-to-Text comparison tool lets you run that comparison directly.
More guides to explore

Build faster. Ship safer. Scale smarter.
Get started with healthcare-native APIs built to power real clinical workflows.