

We are introducing the top-ranked method for understanding AI models, leading the industry interpretability benchmark.
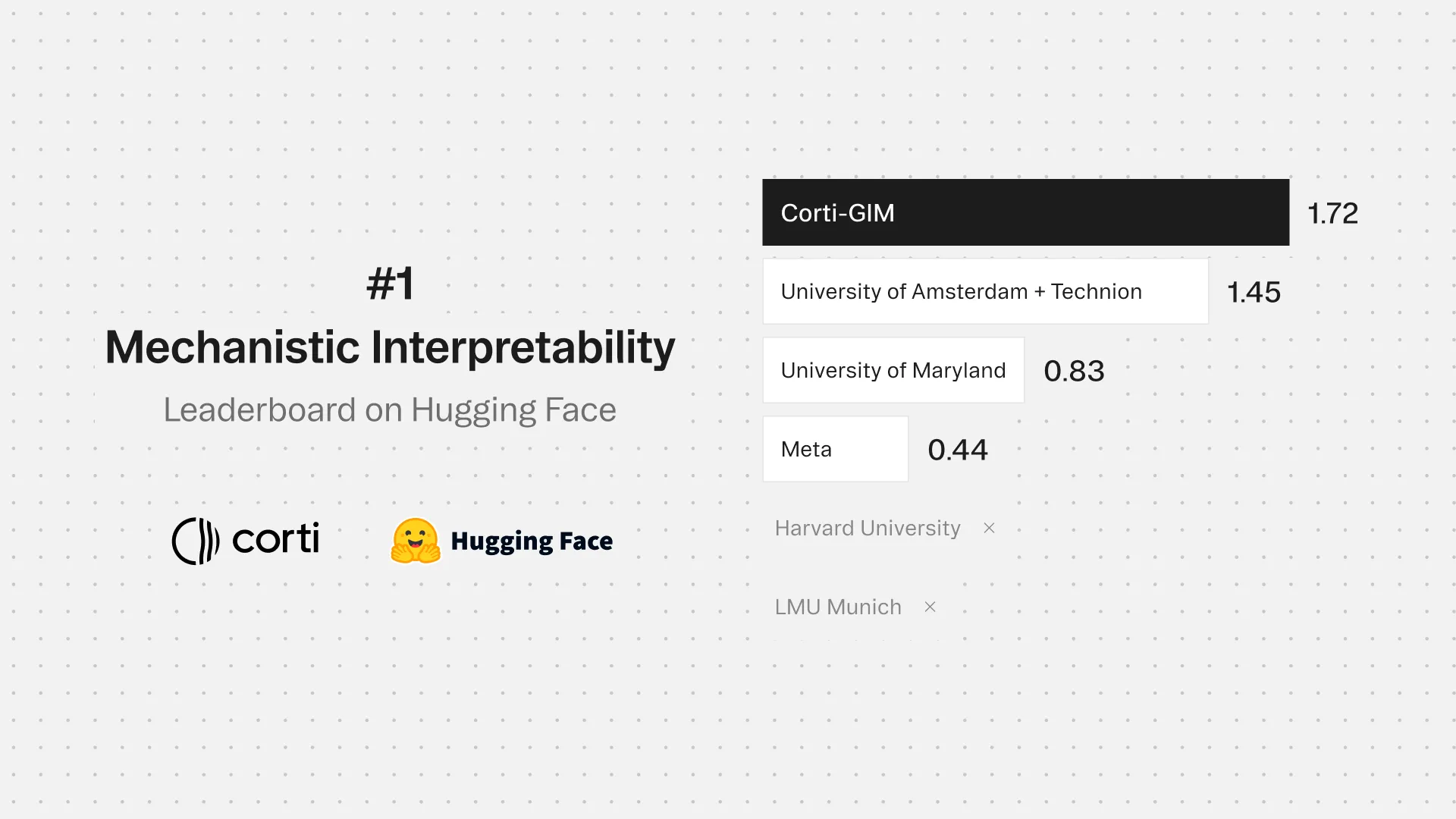
Today, we report a significant advance in circuit discovery for neural networks. We have developed GIM (gradient interaction modifications), a gradient-based method that achieves the highest known accuracy for identifying which components in a model are responsible for specific behaviors. GIM has topped the Hugging Face Mechanistic Interpretability Benchmark, demonstrating both superior accuracy and production-scale speed.
This is the first interpretability method to top the industry benchmark while remaining fast enough for production-scale models. This discovery could help teams build more reliable AI systems through precision engineering rather than trial and error.
Making AI explainable: Our breakthrough in model interpretability
Large language models have become remarkably capable, but understanding why they work remains one of AI's fundamental challenges. We can measure what these models do, but the mechanisms behind their behavior often remain hidden. Without understanding how models arrive at their outputs, improving them becomes a process of trial and error rather than precision engineering.
We’ve used gradient-based mathematical techniques like back-propagation to build a better tool for revealing how LLMs and other Transformer Architectures work. As of today, this is the world's best performing tool for this, reaching the top of the Hugging Face Mechanistic Interpretability Benchmark.
GIM identifies the neural circuits responsible for specific model behaviors, addressing a critical bottleneck in AI development. And because it uses gradient-based methods, it runs efficiently on production-scale models.

Understanding the LLM black box
When training neural networks, we're not programming them in the traditional sense. As Chris Olah from Anthropic describes it, we're "growing" them like biological neural networks. Each time we train a model, it develops differently. The models often work exceptionally well, but we don't fully understand the logic happening inside the billions of connected neurons.
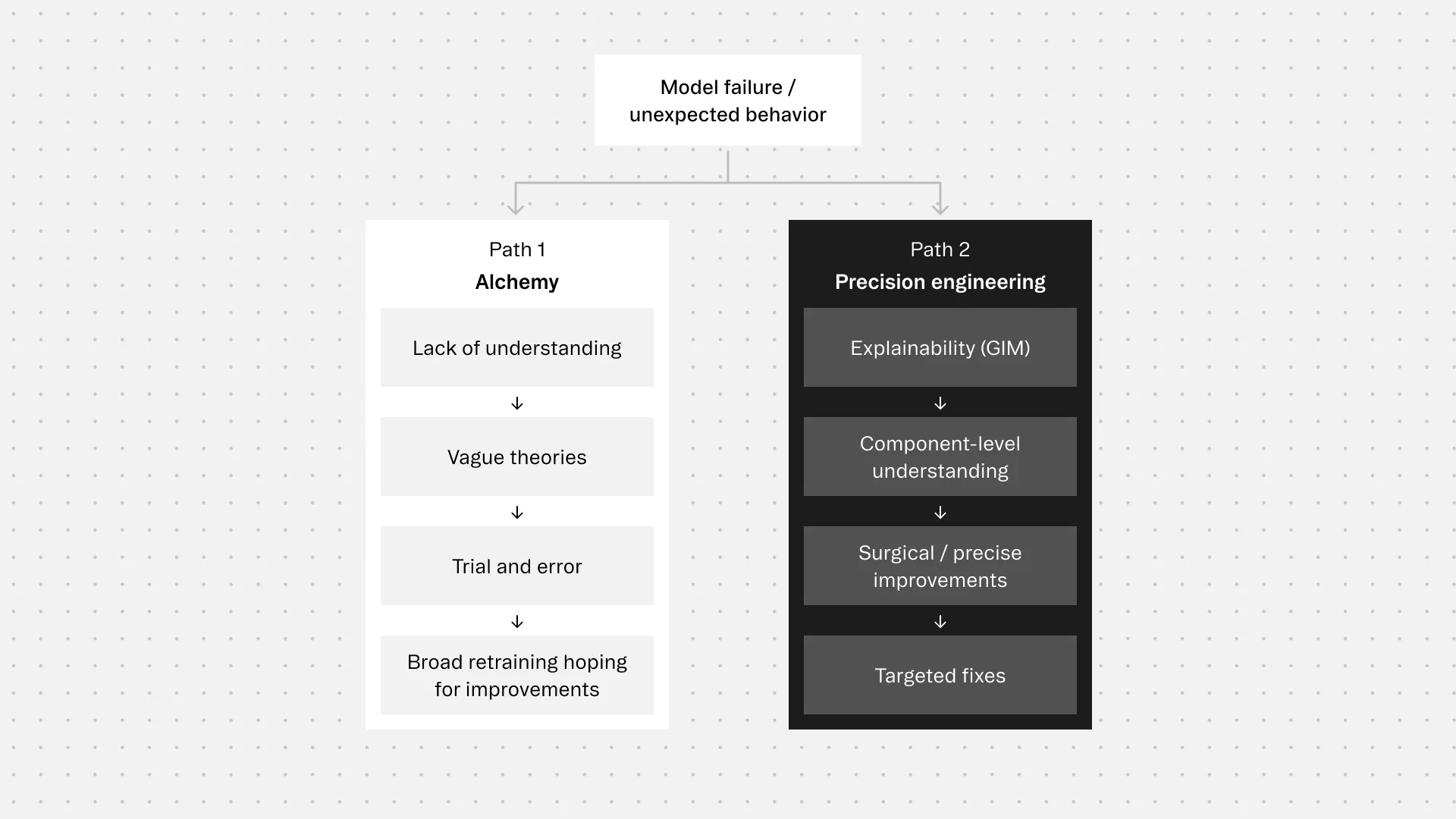
This lack of understanding creates real problems. When models fail or behave unexpectedly, identifying and fixing the issue becomes difficult. It's hard to improve something you don't understand. Until now, much of AI development has been what you might call alchemy: trying things out based on vague theories that are somewhat correct at an abstract level, but not really precise.
Mechanistic Interpretability is the field of study that addresses this challenge. It aims to understand how models work under the hood, much like neuroscience studies the brain. One key approach is circuit discovery, the foundation upon which GIM was built, identifying the specific neurons and connections that contribute to particular behaviors.
Introducing GIM: A path to faster AI model advancement
GIM (Gradient Interaction Modifications) is our method for revealing which parts of a model are responsible for specific behaviors. It tops the Hugging Face Mechanistic Interpretability Benchmark, the industry standard maintained by researchers from MIT, Stanford, Cambridge, Boston, and ETH Zurich.
This means we can now identify the circuits behind specific model behaviors faster, cheaper, and more accurately than any other available method. When models fail or behave unexpectedly, GIM helps pinpoint the specific components causing the problem. Instead of broad retraining or vague adjustments, teams can target the actual circuits that need fixing.
This transforms model development from trial and error into precision engineering. For those working on Transformer Architectures like the Large Language Models powering today's most prevalent AI systems, GIM provides the precision diagnostic tool the field has been missing. You can't improve what you don't understand, and GIM gives researchers and engineers their clearest view yet into how these models actually work.
How GIM works: The research enabling faster AI interpretability
GIM addresses a fundamental problem: neural networks contain interactions between components that you miss when testing them individually.
GIM combines two advantages:
- Gradient-based computation makes it fast.
- Interaction modeling makes it accurate.
The core insight is simple. Imagine two light switches where either one being on keeps the light on. Testing each switch alone, you'd conclude neither matters because the light stays on. But turn off both simultaneously, and the light goes out. Neural networks often operate similarly. Components that seem unimportant individually can be essential when considered together.

Previous gradient methods were efficient but failed to account for how components depend on one another. Traditional ablation methods captured interactions but were prohibitively slow. GIM estimates how components would behave if you changed multiple ones simultaneously, making it both faster than ablation and more accurate than existing gradient approaches.
The "self-repair problem": Why traditional interpretability methods fall short
Existing circuit discovery methods face two main obstacles: speed and accuracy.
The most straightforward approach tests each connection individually by disabling it and observing whether the output changes. But with billions of connections in modern models, this sequential testing becomes impossibly slow.
Gradient-based methods offered a faster alternative by estimating all connections' importance simultaneously using back-propagation. However, these methods struggle with self-repair, where neural networks contain backup mechanisms that cause other components to compensate when one is disabled. This masks the original component's true importance. It's like trying to understand the role of the frontal lobe in personality, but discovering the brain has a backup region that takes over when damage occurs.
Vertical AI labs accelerating frontier AI progress
Mechanistic interpretability is a field with significant research investment from Anthropic, DeepMind, and major universities worldwide. These organizations dedicate substantial resources to understanding how models work, motivated by everything from safety concerns to the simple recognition that you can't systematically improve what you don't understand.
Corti is a specialized team focused on AI advancement in healthcare, yet we're now leading in a space where frontier labs have dedicated research teams. This isn't surprising when you understand what drives vertical AI labs.
Precision is what we do. In healthcare, we can't afford vague improvements or trial-and-error approaches. We need to know precisely why a model behaves a certain way, identify the specific components causing issues, and fix them surgically. This demand for precision doesn't just make our healthcare products better. It pushes us to develop methods that advance the field as a whole.
The implications extend beyond our use case. Instead of making broad changes to training data and hoping for improvements, teams can identify specific problematic circuits and modify them directly. This means faster development cycles, models that behave as intended, and more reliable systems.
When vertical labs advance fundamental AI research, they accelerate progress across the entire field. Domain expertise and real-world deployment constraints drive innovations that benefit everyone. GIM demonstrates this dynamic in action.
Precision is what we do. In healthcare, we can't afford vague improvements or trial-and-error approaches.
Open-sourcing the leading interpretability method
The best interpretability tools shouldn't be locked behind organizational boundaries.
GIM achieves the highest known accuracy for circuit discovery while remaining fast enough for the largest models. These capabilities matter for every AI application, from research to production systems. By open-sourcing GIM, we're giving the community the precision tools needed to build AI systems we can actually understand and improve.
Developers can access our implementation via a Python package compatible with any transformer-based model. The package includes all three modifications and integrates seamlessly with existing workflows. Whether you're researching model behavior, debugging unexpected outputs, or building more reliable AI systems, GIM provides faster and more accurate circuit discovery.
import gim
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("gpt2")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
input_ids = tokenizer("The capital of France is", return_tensors="pt").input_ids
attributions = gim.explain(model, input_ids, tokenizer=tokenizer)
# attributions is a tensor of shape [seq_len] with importance scores per tokenBeyond discovery: Building better AI systems
Circuit discovery represents the first step in understanding artificial neural networks. The next challenge is leveraging these insights to improve models systematically. We're continuing to refine GIM and explore its applications across different model architectures and tasks. We're also investigating how circuit-level understanding can inform model design, training procedures, and safety evaluations.
The path from alchemy to engineering is long, but tools like GIM mark meaningful progress. As mechanistic interpretability advances, we move closer to AI systems we can understand, trust, and improve with precision.
Build faster. Ship safer. Scale smarter.
Get started with healthcare-native APIs built to power real clinical workflows.


